There is a known issue affecting elixir versions from 1.14.0 to 1.16.0-rc.0: Optimizations (SSA and bool passes, see the original change) had been disabled affecting the performance of functions defined directly in the top level (i.e. outside of any module). The issue was fixed by re-enabling the optimization in 1.16.0-rc.1 (commit with the fix). The issue is best show-cased by the following benchmark where we’d expect ~equal results:
list = Enum.to_list(1..10_000)
defmodule Compiled do
def comprehension(list) do
for x <- list, rem(x, 2) == 1, do: x + 1
end
end
Benchee.run(%{
"module (optimized)" => fn -> Compiled.comprehension(list) end,
"top_level (non-optimized)" => fn -> for x <- list, rem(x, 2) == 1, do: x + 1 end
})
The benchmark yields roughly these results on an affected elixir version, which is a stark contrast:
Comparison:
module (optimized) 18.24 K
top_level (non-optimized) 11.91 K - 1.53x slower +29.14 μs
So, how do you fix it/make sure a benchmark you ran is not affected? All of these work:
benchmark on an unaffected/fixed version of elixir (<= 1.13.4 or >= 1.16.0-rc.1)
put the code you want to benchmark into a module (just like it is done in Compiled in the example above)
you can also invoke Benchee from within a module, such as:
defmodule Compiled do
def comprehension(list) do
for x <- list, rem(x, 2) == 1, do: x + 1
end
end
defmodule MyBenchmark do
def run do
list = Enum.to_list(1..10_000)
Benchee.run(%{
"module (optimized)" => fn -> Compiled.comprehension(list) end,
"top_level (non-optimized)" => fn -> for x <- list, rem(x, 2) == 1, do: x + 1 end
})
end
end
MyBenchmark.run()
Also note that even if all your examples are top level functions you should still follow these tips (on affected elixir versions), as the missing optimization might affect them differently. Further note, that even though your examples use top level functions they may not be affected, as the specific disabled optimization may not impact them. Better safe than sorry though 🙂
The Fun with Optimizations
A natural question here is “why would anyone disable optimizations?”, which is fair. The thing with many optimizations is – they don’t come for free! They might be better in the majority of the cases, but there is often still that part where they are slower. Think of the JVM and its great JIT – it gives you a great performance after a warmup period but during warmup it’s usually slower than without a JIT (as it needs to perform the additional JIT work). If you want to read more on warmup times I have an extensive blog post covering the topic.
So, what was the goal here? As the original PR states:
Module bodies, especially in tests, tend to be long, which affects the performance of passe such as beam_ssa_opt and beam_bool. This commit disables those passes during module definition. As an example, this makes loading Elixir’s test suite 7-8% faster.
José Valim
Which naturally is a valid use case and a good performance gain. The unintended side effect here was, that it also affected “top level functions”/functions outside of any module which in 99.99% of cases doesn’t matter and can be ignored. Let me reiterate this, this should not have affected any of your applications.
The problem here is that benchee was affected – as for ease of use we usually forego the definition of modules (while it’s completely possible). And well, optimizations not being in effect when used with a benchmarking library is quite the problem 😐 😭 Hence, this blog post along with a notice in the README to raise awareness.
So, if you ran benchmarks on affected elixir versions I recommend checking the above scenario and redoing the benchmarks with the above fixes applied.
On the positive side, I’m happy how quickly we got around to the issue after it was discovered, Jean opened the issue only 4 days after it was fixed in elixir and a day after it was released as part of the 1.16.0-rc.1. So, huge shout out and thank you again!
And for even more positive news: does this now mean our tests load slower again just so benchee can function without module definitons? No! At least as best as I understand the fix, it increases the precision by disabling the compiler optimizations only in module bodies.
After making it through the initial application selection and conquering a first set of introductory interviews the interview process often moves on to some form of “technical challenges”. The goal here is to check your skills on a practical task in the area you will be working in. Oftentimes they are used to sort out people that can just talk “nicely” about doing things vs. actually doing them. The challenges will often be a basis for further conversation. Challenges can take many forms, and so this post will first give some general tips and then dive into the different forms they can take and what to look out for.
The focus of this post will be engineering, as that’s what I know best, but a lot of the general tips should be generally applicable. We’ll first look at a good mindset and some general tips. Then we move on to different challenge setups – namely, is it take-home challenge or a live challenge. To round things out we’ll examine different challenge topics: Coding, Pull Request Review, Architecture & People Manager.
Who am I to speak on challenges in interviews? I’ve done quite a few of them myself and also was the one grading them on many (> 100) occasions as well as teaching people how to grade them. Thanks to my friend Sara Regan for proofreading and providing suggestions.
As a small disclaimer, of course these tips are biased towards how I grade challenges and how it has been done at companies I work at. There are probably people out there who are not interested in you deliberating options and just want you to quietly solve a challenge. If they exist, I’d say they are by far the minority. That said, of course people can also have valid different opinions and approaches to this. Grain of salt applied.
This part of a blog post series I’m writing covering:
Let’s get in the right mindset to tackle the challenges ahead.
The most important thing that I think most people get wrong about technical challenges: It’s less about IF you can solve it, but about HOW you solve it.
Many times I’ve seen someone seemingly half-ass a challenge as they regarded it just as a small hoop to jump through to get to the “real” interviews. This is often exacerbated by the problems given out to be perceived as “toy problems” that are easily solved. This was perhaps most showcased in an interview where the candidate was refusing to implement FizzBuzz instead showing an online solution that worked with a precisely initialized randomness generator. Solving it is not the point.
Most challenges will include something akin to “treat it as if it was real production code you wanted to work on with a team” or something to that tune. I can only implore you to take them seriously. In many cases, whoever is reviewing the challenge doesn’t know you or your background and they can’t assume you know something. Put yourself in their shoes: they want to hire someone and can only assume that during the hiring process you’re trying to show your best self. Even if they don’t assume that, they might see other people who are more diligent and will be more likely to give them the job. Fair or not, this is what they have to go by to see if you’re a fit for the company and also at what level they think you can work at.
You may also be surprised by the statement that they don’t know you, after all this is already after a couple of rounds of interviews – they must know you, right?! Well, it depends on the company but many companies try to remove biases from the process as much as they can. That means that especially people who grade take home challenges or do an in person technical challenge with you often haven’t seen your CV nor have they been in a previous interview. Their task is to judge your proficiency solely based on the challenge. And so, give it your best to leave the best impression. This is not the case everywhere, especially small companies can’t afford to do this. However, it’s still relatively common these days as far as I’m aware.
General Tips
Let’s start it off with some quickfire tips for all challenges – coding, people manager, case study – before we go into more detail:
Take the challenge seriously (yes, I’m a broken record on this), this is an interview situation – it’s fair to assume that they expect you to bring your best and you really should. Aim to deliver high quality and if in doubt mention what you’d do normally and say why you don’t right now or ask the interviewers if you should.
Communicate your thoughts and decisions! As I said, it’s about how you solve a problem, people can’t peek into your thoughts so make them accessible to them.
Record questions you asked yourself
Communicate decisions you have made along alternatives you considered and their tradeoffs
If you don’t know how something is meant, ask the interviewers esp. about ambiguity. I have seen many challenges where ambiguity in the challenge description was part of the challenge design to see how you deal with ambiguity and how you try to clarify it. Asking questions about the problem or even how far the solution should go usually nets you bonus points. Especially if you are unsure about a question or requirement make sure to clarify your understanding to avoid going off in the wrong direction as much as possible
Go through company values and the job posting again before solving any of the challenges. They give you an idea of what to focus on. If “documentation” is one of the company values and you provide none, that doesn’t spell well for you. If a major part of your future job is solving database performance problems, you should make sure your schema and query design in a coding challenge are immaculate.
Nobody expects you to be perfect, a mistake or even a couple mistakes don’t disqualify you. Keep going.
Sadly, not all challenges, interviewers and reviewers are good. Some of them are pretty bad actually, due to a host of reasons (sometimes unqualified engineers are thrown into the mix of interviewing). Try to follow the tips to make the best out of the situation, but I’ve even heard of interviewers refusing to engage in questions about the task. Always remember that interviewing is a two way filtering process – it’s fine for you to decide that you don’t want to work for this company. I have once aborted an interview process because I was sure that what they filtered for with the interviews as I experienced them was not a culture I’d like to work in.
Challenge Setup
Generally speaking, there are 2 types of challenge setups – you can take the challenge home and solve it on your own time or you may need to solve it live on the premises (“in person”). Both challenge setups have their peculiarities, so let’s take a look at them.
Take-Home Challenges
Usually you get sent the challenge and then have a week or 2 to solve them. They usually also fall into 2 categories (or a mix), challenges that are just graded by someone or challenges that you bring with you to the next interview to discuss them with someone.
Here’s what to look out for specifically (while the general tips still apply of course):
Sadly, most of the challenges will take more time to solve them than advertised. I don’t know why this is, but I usually think that someone comes up with an idea that tests as many things they deem important and then pack them all into the challenge. They then make the typical “guesstimate” how long they take to solve and are off by the usual factor of 2-3x. If it takes longer than you’re willing to invest, make sure to communicate it in the challenge or better even ask your contact person. As in: “I don’t think I can finish the challenge due to time constraints, can I get more time please or alternatively could you please tell me if I should rather focus on finishing all the requirements or on writing tests?”
Taking into account the above, make sure that you have enough time during the allotted time frame to solve the task without depriving yourself of sleep. Also be careful not to splatter your schedule with too many coding challenges at once.
Especially with take-home challenges document your major decisions, as you may not be there for the reviewer to ask questions. Be proactive about this. For coding challenges I’d feature a section in the README about decisions taken and then also reference it from relevant parts of the code via comments – make it impossible for the reviewer to miss. They’re also human and make mistakes after all.
If you think something would be too much to include right now or you can’t fit it in due to time constraints, again document it. A common case in a coding challenge would be “normally I’d put this in a background job queue, but due to time constraints I’ve decided to leave it inline for now”.
Review your entire challenge before submission with the mind of a reviewer. Read the challenge description again and make sure you covered all the points.
If the take-home challenge is the subject of a later interview, make sure to re-review your own challenge before the interview. Sometimes a month or more can pass between you completing the challenge and the interview – you should be intimately familiar with it.
Live Challenges
These are challenges where you are presented with the challenge in an interview setting while the interviewers are present. Sometimes you are given a short time (~30 minutes) by yourself to study and prepare, sometimes everything is done on the spot. This is often an extremely stressful situation, but if your interviewers are any good they’re aware of that and will try to make it as comfortable as possible for you.
These tips are also applicable if you first solved a take-home challenge but are then discussing it in a later interview.
Ask clarifying questions! About the problem in the challenge, about how you are expected to solve it and about what you can do (“Can I google?” – answer should usually be yes). This gives you the benefit that you know exactly what you should be doing, but also gives you some time to already think about the challenge and calm down.
Restating the core of the challenge in your own words is a great way to absolutely positively make sure that you’re on the same page as the interviewers about what the task is. For challenges, I like to keep my own bullet points on what is required – for instance at the top of the file for a coding challenge.
Come well prepared. A live challenge should never be sprung on you out of the blue. For a coding challenge make sure that you have your programming environment completely set up as you need it and confirmed working. At best, create a small sample project before at home with all the basics setup working. You don’t want to start installing Ruby & VS Code during your interview.
Also, be aware that if done on your personal laptop (no matter if remote or locally) people will likely see your desktop so make sure it’s presentable
Turn off notifications/communication programs in advance so that you don’t get distracted and so that your interviewers don’t see something they shouldn’t see
Everybody understands that it’s a stressful situation, take some time to think through the problem, you don’t need to be talking all the time.
However, still remember to communicate major questions you are thinking about or decisions you are considering right now. This helps your interviewers, and they might even help you. For instance, I’d always help people if they were searching for a specific method or how to set up their test environment. The interview shouldn’t be about testing easily google-able knowledge, however sadly some may be.
Some of these will be labeled as “pairing” challenges, 99% of the time it won’t be actual pairing. While the interviewers may help you and discuss problems with you, they usually won’t give you critical solutions or take to coding themselves. I feel the need to mention this, as I always feel that this “pairing” label is deceptive. However, if they do give you suggestions, consider them and elaborate on them.
Sometimes the challenge isn’t even designed to be doable in the allotted time or there is a base version with multiple “extension points” in case there is time left. A good interviewer will tell you this. If unsure, ask. I have passed coding challenges in the past with flying colors although I didn’t finish it.
Challenge Topic
There are many different main topics for challenges throughout different companies and seniority levels – the most common of which is certainly the coding challenge for developers. They often have their own specifics to go with them no matter if they are take-home or live, so let’s dive into them!
Coding Challenge
An oldie of coding challenges
They are usually part of an engineering hiring process in one form or another. A “trial” day is also a coding challenge in big parts, as in you’re given a problem and are asked to solve it with the people around.
Whether or not coding challenges are good is not the topic of this blog post. I know many programmers hate them with a passion. I can only tell you that I’ve seen candidates with 5+ years of experience that couldn’t explain what a `return` statement does. Especially if you have a lot of open source code it’s common to wish that they’d just review that instead. And that makes sense and some companies do it. However, a challenge comes with the pro that it’s normally standardized across the company, can be the basis of discussion in further interviews and it hopefully probes for skills relevant to the job. For instance, you can say people could just look at benchee when interviewing me, but it would tell you nothing about how I work with databases or web frameworks.
Why am I telling you this? I’ve seen more than a couple of candidates who let their disdain for any type of coding challenge show while they’re solving it or discussing it. That’s not in your best interest – if you take on this step, even if you hate it, handle it professionally.
One more time: Take it seriously! Show your best work!
I mentioned before that challenges often contain a phrase like “production quality” but what does that mean? Here is a small list:
Naturally the application fulfills the task as described
Tested appropriately – in some places missing tests are an auto reject, also make sure the tests actually pass
The application should not emit warnings
Reasonably readable code
No leftovers like TODO comments or out commented code
A README that describes what the application is about and how to set it up
Document the versions of all major technologies you have used (Elixir/Erlang/Postgres version)
It usually does not mean that the application should actually be deployed, although it may earn you bonus points
Similarly, you don’t need to have a CI running unless you want it for your own safety (the amount of challenges I’ve seen that were broken on some ‘last minute refactoring’ is staggering)
Remember that it is more about how you solve it versus if you solve it. You can give an impression of overengineering or underengineering all too easily.
A classic thing I often see is people completely forgetting about any form of separation of concerns, and just mixing as much as possible into a single module as “the challenge is so small”. This is usually not in your best interest, as you want to show how you’d work on a “real” project. Also, it usually makes for overly complicated tests.
On the other end of the spectrum I see people basically making up future requirements that are in no way hinted at in the challenge and so they make their code overly complex and configurable, sacrificing readability.
Both of the above are bad, best document why you did or didn’t do something and say what you could have done differently.
While using linters & formatters is usually not a requirement, they help you catch errors and make it nicer to read for your reviewers. I especially recommend using these if you’re rusty.
It should go without saying, but follow best practices as you know them: Add indexes where appropriate. Don’t use float columns to store money values.
Communicate decisions! For instance, you may have decided not to add an index for a column that is queried because the query is fast enough without it and the application is write-heavy and so the index may do more harm than good. Without documenting this, the reviewer will never know and might just assume you don’t know how to use indexes.
Be mindful that some reviewers will read your git history, avoid cussing out the challenge or company. (yes, this point is here for a reason)
If you use unusual patterns, make sure to explain what they are and why you are using them (and ask yourself if it’s really necessary).
On take-home challenges: Make extra sure to use readable names and add a bit more documentation than you usually would, these are people that don’t know you and can’t ask you. Make the reviewers job as easy as possible.
Especially for take home challenges I’m paranoid that it won’t work on the machine of the reviewer. So, right before submitting I’ll clone the entire repo freshly into a new directory and follow my own setup guide to see that everything works and I didn’t forget to check in a file or forgot a setup step.
Let me expand on “document things” a bit more. I remember a peculiar coding challenge where its design was problematic as it sent all requests through a single central GenSever essentially bottle-necking the entire application. I wrote a whole paragraph on why I think this is a bad design, but still implemented it as the task description specifically asked for it. I then went into how I would implement it differently and what I also did in the current challenge to lessen the negative impact of this architecture.
Some coding challenges you will encounter aren’t truly coding challenges but puzzles. I’ve seen coding challenges that just directed you to an URL and from there you need to figure out the format, get links to CSV files, a text file and then try to figure out what your task is. I can just say that I think these are terrible, try your best to solve them, but also think about what kind of skills the company may be valuing if they choose to test engineers like that.
Lastly the aforementioned FizzBuzz is a well known challenge and well suited to demonstrate what I mean by “taking it seriously” as well as showing how complex a “toy” problem can get. So, I wrote an entire blog post about it and its different evolutionary stages. If you want to dive more into coding challenges, that’s a good next spot to check out.
Pull Request Review
It feels like in recent years “pull request reviews” have become more common as a form of challenge. The premise is simple: You are to review a pull request. Sometimes it’s adding a feature, sometimes it’s building out an entire new application. However, the pull request will always be intentionally bad, so that you have something to fix.
What I like about this kind of challenge is that it’s less likely to go vastly over time while also checking communication skills. So, what should you look out for in particular here:
Again, pretend it’s real. Pretend you’re reviewing a real pull request from a real human being. Be kind, be helpful. One of the easiest ways to fail these is by being an ass.
Proper Pull Request Reviews are a topic of their own (see for instance this post by Chelsea Troy) but in short things that can help:
Also praise good code, don’t focus on just the negatives
Ask questions if you are not sure why something is the way it is
Provide suggestions on how to change things, if you recommend to use a particular method best provide a link to its documentation
Make sure to mention why you think something needs changing; “this is bad” comments help no one
Summarize your main points in a final summarizing comment, perhaps offering to also pair on it
Check if the PR actually solves everything that is mentioned in the issue it is trying to solve
Check for readability
Make sure everything is appropriately tested
Be very diligent, many of these challenges also sneak in some form of insecure code the kind of which you hopefully don’t see too often. Don’t overlook something because “they probably know what they’re doing” – it’s a challenge, they likely don’t.
See if tests & linters pass, if there is no CI try to run it yourself. It’s generally best to check out the code yourself to be able to play with it anyhow.
Architecture/Design Challenge
Excuse the hand writing. Some actual notes from an Architecture interview I did.
This is a type of challenge you typically only face at the level of Senior or above, sometimes it’s also called a “Design interview”. Essentially you’ll be given a scenario for an application and asked to design an application that solves this scenario. Sometimes the scope of this is choosing the entire tech stack and general approach, sometimes the focus is solely on the database design – although the latter will come up in both cases. You will not implement it in code, but you will talk through it and probably draw some diagrams.
Ask about the requirements for the application, chances are that there are things that aren’t completely spelled out but could have an impact. At the very least, you can make sure to arrive at a common domain terminology. Some questions that might make sense to ask for a web application:
Who uses the application? What for?
Will there only be a browser client for this or do we have other possible clients as well?
What kind of traffic can we expect? Will it be spiky?
What is the expected response/processing time?
How much data will we need to store approximately?
Are all users of the system the same or do we have different roles?
What’s most important to the system: Should it always be correct, always be fast or always be available?
… and of course many more, system design is a WIDE topic …
Especially here: make the options you’re weighing known. This interview is all about decisions you make and tradeoffs you consider. Whenever you bring something up, an interesting discussion with the interviewers might ensue. I once deliberated whether we could use Sidekiq in a scenario where we absolutely can’t lose jobs, as I was aware of a related problem in the base version of Sidekiq. This open deliberation seemingly impressed my interviewers, had I kept it to myself they would have never known.
Be visual, draw diagrams of the application, its major components and its environment as well as the database design. All of that is the basis for the discussion and can help you spot inconsistencies. At best the interviewers provide you with a diagramming tools/whiteboard, but even if they don’t a piece of paper and a pen work just as well. The last time I did this I noticed that I had a dangling 1-to-1 that was related to only one table and basically only featured one meaningful column. While it seemed to make sense, I discussed the issue with the interviewers and we decided to “inline” that table again.
Take your time to review your own design and discuss it, that way you can bring more options to the table and fix it up – all that before the interviewers get to ask their first question.
Deliberate the pros and cons of your choices and make sure they fit the scenario. You may love microservices, but if you’re designing a system for a small 3 person business that is used a hundred times a day for the foreseeable future it’s probably not the best decision.
Be upfront that you might not know something as well. For instance, you might figure out that for what you’re going to build some form of message queues may be a good fit, but you haven’t worked with them a lot. This tip may be controversial, however pretending to know something that you don’t is one of the easiest ways to fail interviews. If the interviewers are good and aware you’re not as familiar with the technology, they might proactively help you out or appreciate the thought but encourage you to go with a technology you’re more familiar with.
People Manager Challenge
Many companies will have specialized people manager challenges for Team Leads/Engineering Managers and up. These can come in many different forms, most of them will put you in some sort of contrived scenario with a problem and then ask you how you would go about solving that problem. More often than not, the scenario will include some form of conflict involving your reports. The form that these take varies wildly:
You might get a conflict scenario and simply be asked what you think is happening and how you’d address it.
You may get posts on an internal “help” forum and be asked to answer them.
You may also be given a scenario of a team that is underperforming and be asked to help them as their new manager.
This challenge type is very different from the others and arguably more complex: You’re dealing with humans and organizational structures here. And worst of all, they are not real and context is only established via a 1-2 page briefing. There is no code you can look at and fiddle with. As a result of this, be extremely careful how you approach and answer these. You simply can not know many things for certain, make it clear that what you are noting are deliberations and ideas. Still, look at all the people in the scenario and try to figure out what is happening. What misunderstandings could there be? Are there biases at play? How can you figure it out? The solution almost always includes talking to all involved participants to get their sides of the story.
As in real life, the scenario as described is subjective. Don’t take all information and statements contained in the task description as the absolute truth. For instance, a team may be described as “underperforming” – it would be important to establish how that was determined and what it means. Maybe the team is working on a major project people are unaware of. Maybe they’re the ones actually keeping the money making legacy application alive and are hence not contributing as much to the new shiny thing (™).
In whatever way you discuss the challenge – be it talking to interviewers about the task or notes you hand in to them – make sure that your thoughts are easy to follow. Be deliberate to distinguish your levels of certainty about different aspects. Make sure you don’t just write down “Talk to Sara” but why you want to talk to her, what piece of the puzzle you want to understand there.
Closing up
And that’s another whopper about interviewing in the books. It’s a complex topic and I truly wish to expand even more on some aspects – but I won’t do it right now so that it stays half-way readable and my time invested stays… not too outrageous.
Try to show your best self, take the tasks seriously and treat them as if they were real as much as possible. Make people aware of the tradeoffs you’re deliberating and why you’re taking certain decisions. It’s not just about solving the task, but about how you solve it – and for the interviewers to understand that you have got to make it obvious to them. Don’t be afraid to discuss the challenge itself with them.
Remember as always, interviewing is not a perfect science. You can fail these challenges for all kinds of reasons – and quite some of them have nothing to do with your ability to do the actual job. If you know you struggle with “Live” challenges, try to get some practice in. Be it mock interviews with friends or applying at another company that isn’t as important to you first.
Last week I found myself at my old RailsGirls/code curious project group the rubycorns coaching a beginner through the FizzBuzz coding challenge. It was a lot of fun and I found myself itching to implement it again myself as I came up with some ideas about a nice solution given a requirement for arbitrary or changing rules to the game.
I’ve also been working on blog posts helping people interview processes, the next of which will be about Technical Challenges/Code challenges (due to be published tomorrow! edit: Published now!). This is a little extension for that blog post, as an example of going through and improving a coding challenge.
To be clear, I don’t endorse FizzBuzz as a coding challenge. In my opinion something closer to your domain is much more valuable. However, it is (probably) the most well known coding challenge so I wanted to examine it a bit. It is also deceptively simple, and so deserves some consideration.
So, in this blog post let’s start with what FizzBuzz is and then let’s iteratively go through writing and improving it. Towards the end we’ll also talk about possible extensions of the task and how to deal with them. The examples here will be in Ruby, but are easy to transfer to any other programming language. If you’re only here for the code, you can check out the repo.
The FizzBuzz Challenge
The challenge, inspired by a children’s game, originated from the blog post “Using FizzBuzz to Find Developers who Grok Coding” by Imran Ghory back in 2007 – the intent being to come up with a question as simple as possible to check if people can write code.
The problem goes as follows:
Write a program that prints the numbers from 1 to 100. But for multiples of three print “Fizz” instead of the number and for the multiples of five print “Buzz”. For numbers which are multiples of both three and five print “FizzBuzz”.
Simple enough, right? Well, I think it actually checks for some interesting properties and is a good basis for a conversation. To get started, let’s check out a basic solution.
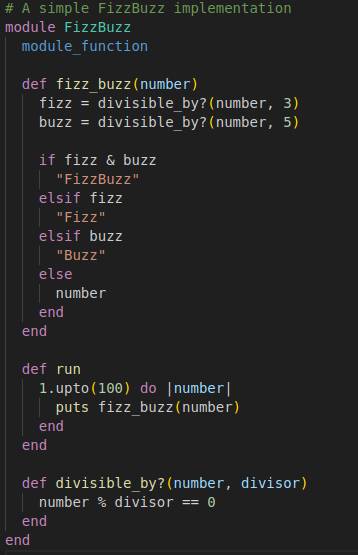
Basic Solution
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
That one does the job perfectly fine. It prints out the numbers as requested. It also helps to illustrate some of the difficulties with the challenge:
First off, printing out the results is interesting as it is notoriously hard to test (while possible given the correct helpers). It should push a good programmer towards separating the output concern from the business logic concern. So, a good solution should usually feature a separate function fizz_buzz(number) that given any number number either returns the number itself or ”FizzBuzz” etc. according to the rules. This is wonderfully easy to test, but many struggle initially to make that separation of concerns. We’ll get to that in a second.
What I don’t like about the challenge is that it requires knowledge about the modulo operator, as it isn’t commonly used, but you need it to check whether a number is actually divisible. Anyhow, there will be a lot of code like: number % 3 == 0. To avoid repetition and instead speak in the language of the domain it’s much better to extract this functionality into a function divisible_by?(number, divisor). Makes the code read nicer and removes inherent duplication.
Speaking of the division, the order in which you check the conditions (namely, being divisible by 3 and 5, or 15, before the individual checks) is crucial for the program to work and I’ve seen more than one senior engineer stumble upon this.
With that in mind, let’s improve the challenge!
We need to go back
First off, while the previous solution is “perfectly” fine, I’d probably never write it as it’s hard to test – it’s just a script to run and everything is printed to the console. And since I’m a TDD kind of person, that won’t do! I usually start, as teased before, by just implementing a function fizz_buzz(number) – that’s the core of the business logic. The iteration and printing out are just secondary aspects to me, so let’s start there:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Much better, and it’s tested! You may think that the test generation from the hash is overdone, but I love how easy it is to adjust and modify test cases. No ceremony, I just add an input and an expected output. Also, yes – tests. When solving a coding challenge tests should usually be a part of it unless you’re explicitly told not to. Testing is an integral skill after all.
Ok, let’s make it a full solution.
Full FizzBuzz
Honestly, all that is required to turn it into a full FizzBuzz solution is a simple loop and output. What is a bit fancier is the integration test I added to go along with it:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Simple isn’t it? You may argue that the integration test is too much, but when I can write an integration test as easy as this I prefer to do it. When I write code that generates files, like PAIN XML, I also love to have a full test that makes sure when given the same inputs we get the same outputs. This has the helpful side effect that even minor changes become very apparent in the pull request diff.
Anyhow, the other thing that we see is that our separation of concerns with the fizz_buzz(number) function pushed us to here is that there is only a single puts statement. We separated the output concern from the business logic. Should we want to change the output – perhaps it should be uploaded to an SFTP sever – then there is a single point for us to adjust that in. Of course we could also use dependency injection to make the method of delivery easier to change, but without a hint that we might need it this is likely overdone. Especially since I’d still want to keep the full integration test we just wrote, programs have a tendency to break in the most unanticipated ways.
Keeping up with the Domain
The other thing I complained about initially was the usage of the modulo operator. Truth be told, I only wrote the initial version like this for demonstration purposes – that one has to go. I don’t want to think about what “modulo a number equals 0” means. Whether or not something is divisible is something I understand and can work with. It also removes a fair bit of duplication:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Much better! There is a small optimization here, where we only check the divisibility twice instead of 4 times. It doesn’t fully matter, but when I see the exact same code being run twice in a method and I can remove it without impacting readability I love to do it.
I consider this a good solution. However, now is where the fun of many coding challenges starts – what extension points are there?
Extension Points
Many coding challenges have potential extension points baked in. Some extra features, or, what I almost prefer dealing with, uncertainty and how that might affect software design.
How certain are we that we need the first 100 numbers? How certain are we that we want to print it out on the console? Is there a possibility that we’ll get a 3rd number like 7 and how would that work? How certain are we that it’s the numbers 3, 5 and the words Fizz and Buzz?
Depending on the answers to these question you could go, adjust the challenge to make these easier to change. And with answers I don’t mean you making them up, but in case of a live coding challenge you talking to your interviewers to see what they think. A common case for instance would be that the numbers and strings may change while we’re certain it will be 2 numbers and 2 distinct strings – “product is still trying to figure out the exact numbers and text and they might change in the future as we’re experimenting in the space”.
Let’s run with that for now – we think it will always be 2 numbers but we’re not sure what 2 numbers and we’re also not sure about Fizz and Buzz. What do we do now?
Going Constants
One of the easiest solutions to this is to extract the relevant values to constants or even into a config.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Right, so that got a lot longer and frankly also a bit more confusing. However, it is now immediately apparent where to change the values. That said, we also kept the “FizzBuzz” naming for the constants which may get extra confusing if we changed the text to something like “Zazz”. It’s always a tradeoff, the previous version was definitely more readable. We did get rid of “Magic numbers” and “Magic Strings”. Sadly, due to the nature of the challenge, they are also still very magical as there is no inherent reasoning to them 😅
Something bugs me with this solution though, and that’s the reason why I actually went and implemented it myself again (and wrote this post): There is an obvious relation between FIZZ_NUMBER and FIZZ_TEXTbut from a code point of view they are completely separate data structures only held together by naming conventions and their usage together.
Working With Rules
Ideally we’d want a data structure to hold both the text to be outputted and the number that triggers it together. There’s a gazillion ways you could go about this. You could simply use maps, arrays or tuples to hold that data together. As we’re doing Ruby right now, I decided to create an object that holds the rule and can apply itself to a rule – either returning its configured text or nil.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Now, that’s quite different! Does it work? Well, yes – and the beauty of it is that so far we haven’t altered our API at all so all of these were internal refactorings that work with exactly the same set of tests. Yes, technically this adds additional optional parameters, we’ll get to these later 😉
The most interesting thing about this is that the rule of “if it is divisible by both do X” is gone. Turns out, that rule isn’t really needed:
if it is divisible by 3 add “Fizz” to the output
if it is divisible by 5 add “Buzz” to the output
if it is divisible by neither, just print out the number itself
That works just as well. It means that the order in which we store rules in our DEFAULT_RULES array matters (so we don’t end up with “BuzzFizz”). Of course we need to verify this with our stakeholders/interviewers, but let’s say they agree here. Now, can we allow for even more flexibility with the rules?
Flexible Rules
Now our “stakeholders” might come back and say well, you know what we’re not so sure about just having 2 numbers and their respective outputs. It may be more, it may be less! The good news? This already completely works with our implementation above. However, we should still test it. You can take a look at all the test I wrote over here, I’ll just post the tests here for adding a 3rd rule: 7 and Zazz!
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As per usual, testing all the different edge cases here is a fun exercise:
What is the behavior if no rules are passed?
What happens if the exact same rule is applied twice?
Can I change the order to make it “BuzzFizz”?
What I also like about this solution is that the rules aren’t actually hard coded but are injected from the outside. That allows us to easily test our system against many different rule configurations. It also allows us to run many different rule configurations in the same system – each user of our FizzBuzz platform could have their own settings for FizzBuzz!
Closing Out
That’s quite a bit of changes we went through here. I want to stress, that you shouldn’t start with the more complex solution as it is definitely harder to understand. You Ain’t Gonna Need It.However, if there are actual additional requirements or credible uncertainty it might be worth it. I ended up implementing it because I wanted to translate that relationship between “3” and “Fizz” explicitly into a data structure, as it feels like an inherent part of the domain. The other properties of it were almost just a by-product.
You can check out the whole code on github and let me know what you think.
Of course, we haven’t handled all extension points here:
The range of 1 to 100 is still hard coded, however that is easily remedied if necessary (by passing the range in as a parameter)
Our choice of the implementation of Rule hard coded the assumption that rules only ever check the divisibility by a number. We couldn’t easily produce a rule that says “for every odd number output ‘Odd'”. Instead of providing Rule with just a number, we could instead use an anonymous function to make it even more configurable. However, don’t ever forget you ain’t gonna need it – even in a coding challenge. Overengineering is also often bad, hence the conversation with your stakeholders/interviewers is important as for what are “sensible” extension points.
The output mechanism is still just puts, as mentioned earlier dependency injecting an object with a specific output method instead would make that more configurable and quite easily so.
Naturally, naming is important and could see some improvement here. However, with completely made up challenges having good naming becomes nigh impossible.
Anyhow, I hope you enjoyed this little journey through FizzBuzz and that it may have been helpful to you. I certainly enjoyed writing that solution 😁
Edit: Earlier versions of the code samples featured bitwise-and (&) instead of the proper and operator (&&) – both work in this context (hence the tests passed) but you should definitely be using &&. Thanks to my friend Jesse Herrick for pointing that out. Yes the featured image is still wrong. I won’t fix it.
I’m glad that that’s all, not to say I don’t have ideas on what else to improve although I won’t promise things. It’s great that benchee just works. It’s a mature piece of software that works well. We need to move away from declaring projects that haven’t seen a release in a while as “dead”. That said, of course some occasional updates on the repo to make sure they work with the most recent versions would be nice.
In particular I’m happy that benchee already started out with warmup as simply the right thing to do(tm). So, when erlang implemented a JIT I had nothing new to do as I new benchee already supported it perfectly.
And that’s also true for all of benchee’s “sister” libraries. I took some time for some house cleaning today to fix their CIs and run them against all the newest versions and… none of them needed any meaningful adjustment that would warrant a new release. That makes me happy.
Applying at and interviewing for a company is potentially one of the most valuable skills one can have – it’s not important for the job, but it’s important for you to get the job. It’s often a bit of a mystery how it all works while many pitfalls await you around the corner – but it doesn’t have to be that way! It’s not always easy to figure out what to do and I’ve even seen the most senior people make basic, but huge, mistakes. Let’s remedy that!
Over my career I’ve done a lot of interviewing: working at a startup, I owned the entire process from application screening to hiring decision. At Remote I did way more than 100 interviews from Junior all the way up to Staff Developers and Engineering Managers. For this article, I called in the help of my friend Pedro Homero, an experienced recruiter, to add his knowledge to this article as well – and add he did! My friend Eleni Lixourioti also gave it another read to make sure things are in shape. Thank you both! 💚
The post will be focused on engineering positions, but this first part is general enough that most of it should apply to all positions. This first part? Yes, there will be follow up parts about coding challenges and technical interviews.
Allegedly this post should have been split up as it is gargantuan in size, but as all of these parts flow into each other and require the same mindset it seemed too difficult to do so… and so I decided to stick with it as is. Take a break in between if you feel like it 🍵
This part of a blog post series I’m writing covering:
CV, cover letter & screening interview ←you are here
Before we get to the actual tips and guidelines, the most important thing to understand when you’re preparing your resume and cover letter is this: What helps them make a hiring decision about me? How can I present myself in the best light? Why should they choose me?
Especially at big companies it’s not uncommon for people to have to comb through hundreds of applications. Sometimes the people doing the pre-screening have little subject matter knowledge. They’re often stressed and have more work ahead of them. Make it easy for them to understand how you can contribute to the company.
It’s also important to understand that interviewing is not a perfect science: mistakes are made constantly. How to design a good interview process asks for its own blog post. But it’s important to remember two things:
You can get rejected from a position although you did everything right and would be a good fit. Mistakes happen or someone else was also a great fit and was chosen.
It’s easy to look at some of the tips further down and say “It should not be like that, the process is broken!” and you may be right, but it’s still what we have to deal with. We have to do the best we can with an imperfect world.
Before you apply: Get to know the company
I’m an avid believer in quality over quantity for applications. Take some time to get to know the company and the position you’re applying for. It will pay off during the process. You might even end up not wanting to work at the company at all any more – in which case you save yourself the time of the entire process!
Here’s some things you should do before you apply:
Read the job posting carefully, take note of the requirements (remember you don’t have to fulfill all of them) and think about which ones you fit well or exceed. Take note of what seems most important to them. For instance, they may be looking for engineers who have experience working in Finance or with big monoliths.
Check out the company:
What is their business model? How does it work and how do they make money? You should be able to do a very basic explanation of their business model before your first interview as that will give you extra points in the interviewers mind.
Do they have a public handbook or company information? Check out things such as their company values, work culture and others.
Check out employee ratings (such as glassdoor). There will always be disgruntled employees, but a lot of negative ratings all at once speak for something negative going down. Also, if there’s a lot of them concentrated in the last couple of months, something big and bad – like a layoff – is likely to have happened. Check Layoffs.fyi to see if the company is listed there.
Search for news about the company, you never know what you might find
Look for a company blog. Any recent interesting articles? Do they have an engineering blog? What do they write about?
This may seem like overkill to you, but these are quick checks that shouldn’t take you more than about an hour. Why should you do them?
On the positive side, I’ve left a positive impression with hiring managers more than once due to my knowledge. Recently, I said no to a recruitment message of a startup based on the described culture and they were impressed with how well I read it, but also let me know that the information was outdated and we might fit after all.
No matter what you think of company values – a lot of companies use them throughout the entire hiring process to see if a person fits well within the company. Being aware of the values helps you to make sure you highlight related qualities in your application and during interviews. “Which company value speaks most to you?” is also a relatively common interview question.
When you show that you’ve taken the time to check the company and get to know what their values are, you’re not only showing your interest but you’re also able to speak the same “language”. Doing that it’s much more likely that you’ll be deemed a “cultural fit” (while I’d much rather talk about “cultural add”, but that’s a different topic).
I can’t stress this enough, I recently talked to an engineer more senior than me and they failed an interview because they didn’t go through this basic preparation, being left humbled by the experience. Think about it, if you had 2 candidates: one with no idea about your company and the other one knowledgeable and seemingly excited about working there – who would have higher chances of getting hired?
Surely the news section is an exaggeration though, right? I mean… maybe. However, I once ended up freelancing, via an agency, for a company with an open court case pertaining to crimes against humanity. I was horrified and got out of the contract as fast as I could and I wish not to repeat that experience.
Bonus Tip:Don’t apply at your “top company” first, unless you are really comfortable interviewing. A lot of people have some form of nervousness and “rust” around interviews. Apply to a less important, but still interesting, company first to shake off some rust, make some mistakes and then do it all better when you interview at your preferred company.
CV / Resume
Alright, you now know the company and what they do. It’s time to prepare your CV! Again, think about what’s most interesting to them. Keep in mind that sometimes, sadly, interviewers stumble into an interview without having read the CV beforehand. Make it easy for them to see what’s most relevant. My CV is by no means perfect but you can check it out here for some inspiration.
I’ll break down some tips and guidelines in the following sections.
General
Let’s kick it off with some general tips and guidelines regarding writing a CV:
The language of the CV should usually be English, unless the job posting is in another language.
Speaking about language, as a general guideline use past tense for past jobs and the present tense for current jobs or in general current things (you are still a speaker at conferences, for instance).
Make sure your CV length isn’t too long, I’ve seen 13 page CVs that had attached their entire university courses and grades. One to two pages is a good guideline unless you’re either very experienced or do a lot of relevant side activities. For comparison, I’ve now cracked 2 pages for the first time.
Be mindful to adjust the level of detail as you maintain your CV over time, your job from 10 years ago probably isn’t interesting enough to take up half a page. Personally, I’ve been working for 9 years – I’ve removed a lot of detail from earlier positions and reduced my education section down to the bare minimum (degree, grade, university, specialization) – it’s simply not super relevant any more.
Sticking out with a more fancy design can help your chances, as long as it doesn’t impede readability. Don’t do a black background with red headlines – it’s terrible to read. Readability and ease of scanning comes first. Again, CVs should be judged purely on content but we’re all human and a special design can help you be remembered, show dedication or to make the cut at all. My CV doesn’t look too special: it has a clear division of sections to ensure readability, and it uses my favorite green as a highlight color.
Give the file a meaningful name that isn’t just cv, people may be reviewing and looking through 100s of these, so something like firstname_lastname_cv.pdf is advisable.
Unless specified otherwise in the job posting, submit your CV as a PDF. And I mean a “real” PDF here with searchable text, not a PDF that’s just a big image (I’ve gotten these…).
You can use links both on the web and in PDFs, make use of them! Link to the company website of companies, to your open source projects etc. Make sure the links work though.
With all those tips etc. it’s also important to remember that this is your application and your CV! You don’t need to follow all the tips here, be sure to speak in your own voice. I try to put the tips here into context, so you know why they may be a good idea. While many people I talk to could benefit from being a bit prouder of their achievements, also remember to not overdo it and to also be humble. Nobody wants to work with someone who doesn’t acknowledge the contributions of others.
Contact & Introduction
First comes basic information such as your name and email, link to social profiles you want them to see such as github. Many CVs these days feature an introductory text highlighting your core competencies. This can often be a good choice, as it gives you a short form to highlight your most crucial and relevant skills. Put keywords in bold, so as to make those 20 seconds the recruiter uses to skim your CV more valuable. Here’s a simple example:
“I’m a senior backend engineer with a little over 5 years of experience. My main stack is Elixir, Ruby and NodeJS. I’ve worked both for big corporations and fast startups and I’m keen on helping develop interesting products with well-documented, clean and performant code.“
Here are some things that I’ve seen featured on CVs that usually don’t need to be on a CV, although cultural context may apply:
Usually you don’t use a photo on CVs any more
Age
Full Address
Marital status
Gender
If anything, they aren’t providing much value (other than inviting biases) and are saving you some space, when you leave them out.
Experiences
This is the core of your CV – your work experiences and other most relevant experiences. You should generally feature them in reverse chronological order – so, most recent experiences first. This is because your most recent experiences are most likely to be the best indicator of what you can do in a work context. Similarly, usually more recent positions deserve more detail/space than older less relevant experiences.
Work experiences are of course most relevant and should hence come first. If you contribute to Open Source or speak at conferences you can also mention this later in a separate section. Education usually comes last, unless you are fresh out of university, of course.
For each position/entry make sure to list the following:
Position title
Company name
Start date/end date (month/year is enough)
An overall summary of what you did there
Preferably, mention the major technologies you worked with there
I like to start with a small summary of my role in the job, and then have bullet points for some highlights of major contributions you made at the company
If a title doesn’t really reflect what you did at a company, highlight the actual work in the summary as best as you can and maybe also leave a note in the title itself. This is a painful experience I had where in an initial interview it was questioned whether I had the experience to manage ~7 people while I had managed 15 people before. Turns out my job title was “Tech Lead” which many people don’t associate with management.
Embellishing your contributions is (sadly) a common practice, I won’t advocate for it and I know why it happens but make sure to keep it in check. If you say “Setup a deployment process from zero” I should better not find out that you were just the person clicking the “deploy” button every now and then.
Last but not least, you should be able to talk about every experience on your CV for a couple of minutes. I’ve experienced way too many interviews where when asked about a highlight on their CV people could not tell me anything about it. Take those points out, everything on your CV is fair game to ask about.
To have a skills section or not
A big question is usually whether to include a “skills” section or not. I recommend it, due to these reasons:
Yes people can see your skills by carefully reading your previous positions, but having the overview makes it easier for the recruiter to check the mental mark of “knows elixir”.
Some companies employ automated systems to sort through CVs, having the skills spelled out there helps you pass these filters.
Again, remember whoever reviews these is often not a subject matter expert – you might know that LISP is a functional programming language but they might not. So having basic skills written out like “Functional Programming (LISP, Elixir)” or “Version Control (git)” can be helpful.
If you do create a skills section, either avoid rating your skills x/10 or be careful with the grades you give yourself. I don’t care who you are, but the chances of you knowing any technology 10/10 are very slim unless you invented it, and even then I’m skeptical.
Adjusting your CV per application
One of the best tips I’ve ever read about CVs is to adjust your CV based on the company you are applying for. First this may sound nuts, but it can make a lot of sense. This is where your prep work about the position and the company comes into play:
If you worked as both a manager and an “individual contributor” extend and shrink relevant parts depending on what position you apply for. If you do this a lot, it’s advisable to create and maintain 2 “base” versions of your CV – one for management positions, one for IC positions.
Does the job posting mention a minimum of years of experience with a specific technology? Make sure that this is easily verifiable from your CV.
Does the company look for someone with some specific skills or experiences? Expand details about that in your CV and maybe cut less relevant details elsewhere. Here are some examples:
They’re looking for someone with experience around Finance, make sure to highlight that in every position you worked in that domain, and put keywords in bold
I’ve been seeing more companies working on workflow automation, and I actually wrote my Bachelor’s Thesis about this – normally I don’t feature this on my CV any more but for one of these companies I’d put it back on.
An absolute pro tip from Pedro is to have a template that you can easily tweak and where you have black as the color of your text and another color for details, visual elements, maybe name of position or name of company. Now go to the website of the company that you’re applying to, check out what their main color is and use that one for this version of your CV. Some recruiters and other interviewers will notice it and appreciate the touch.
How do you do this? Well, just make a copy and adjust it! Keep both versions in separate folders so that you can still easily keep the canonical naming (first_last_cv.pdf). Be sure to keep every version of a CV you sent around, so that if you get to the interview stage you know what version of your CV they have.
Personally, my CV is generated by a static site page generator and so is stored in git so I can easily create a branch for adjusted versions. I can also easily create 2 different base versions of the CV as all the information is stored in JSON, so I can easily feed 2 different sets of data into the same base CV.
Cover letter
Should you write a cover letter? Yes! I know many see it as an unwelcome chore, but I see it as an opportunity for you to show why you want to work for a company and how you can contribute. And it shouldn’t be a standard cover letter you send to everyone, but one adjusted to the position you’re applying for.
Yes, depending on the company only the recruiter might read your cover letter (if that) but it can also be more: this is somewhat of a me thing, but I’ve read every cover letter of every person I interviewed – ever. It gives you the chance to set up a conversation you want to have, and I wish more people would do it like this. Especially if you’re a career switcher this is your place to highlight what else you can bring to the table. If you don’t fulfill the minimum requirements exactly but have other relevant experience, you can highlight that here. For instance, maybe you haven’t worked with Elixir yet but if you have 6+ years of experience in Erlang then that’s worthwhile highlighting.
Not convinced? Ok then, I’ve worked at multiple companies where the lack of a cover letter or a very lackluster cover letter resulted in automatic rejections. Do I have your attention now? Again, you can say that’s not fair but the reality is many companies are overwhelmed with applications – seeing if you’re interested enough in the job to write a basic specific cover letter can be an effective filtering mechanism.
Also, if a cover letter is marked as mandatory and you just upload your CV another time or put in two sentences and call it a day, think about how that reflects on you in the eyes of the company hiring. They don’t know you and one of the first things you show them is that you’re unwilling to comply with some basic requirements – what may that say about your attitude when you work there? Yes, it may be completely different but you have to understand that at this point companies don’t have much more to go on – try seeing the process through their eyes.
So, how do you write a cover letter then? To me, it has mostly these parts:
Introduction/how did you find the job
Why you want to work at the company, use your research on them and maybe also company values
Highlight, again from your research, how you might contribute to the company
Say thanks and that you’re looking forward to hearing from them
As an example, when applying to Remote, I highlighted how I liked the business model, as I frequently had problems getting remote jobs while working from Germany. I believe I also highlighted my desire to work with Elixir full time and that I liked the company value of “kindness”. I then proceeded to highlight the experience I had gathered working remotely, my Elixir open source projects, talks and community involvement dating back to 2015 (as technically, I did not fulfill the 2 years of working experience with Elixir minimum requirement) along with my public profile and experience interviewing (as I figured the company wanted to grow).
The result of that? The next morning I got an invite for an interview later that same week. I’m not saying it was “just” my cover letter, but I’m certain it played a role. (Note from Pedro: I read Tobi’s cover letter and was immediately impressed!)
The Screening interview
Usually your first interview is a screening interview without technical questions with a non technical person. The preparation for this interview is basically what is mentioned in “Before you apply” above: Be sure you know what the company does and what the position is. As long as you’re nice, engaged and your language skills are passable you should usually pass this interview. It’s more checking for red flags and some basic parameters.
That said, interview processes are different everywhere and especially at smaller companies it can happen that you’ll discuss some more in depth topics such as collaboration or even technical details in the screening call. When I was doing screening interviews, I often asked some technical questions to get a first feel for the technical expertise of the candidate.
Back to the “common” screening interviews, the basics they usually check are:
Salary expectation
Possible start date
Work eligibility
Are you in a big hurry (due to other interview processes?)
The salary question is of course a note-worthy one. I usually try to reverse the question and ask them what their salary range is for the position, as I’d hope that every company has these by now, although they might not share them. If that does not work, remember that the real salary negotiation comes later (and is its whole separate topic). Don’t say something completely outlandish (at best do some research before) and give a realistic number of what you’d like to make. Also beware of the “What did you make at your last role?”-question. You do not need to answer this question, and more importantly, you also don’t need to tell the truth. The question is used to anchor your salary close to what you made before, reducing the space for negotiation and movement. In general, the salary question is often asked here to make sure that both sides don’t invest an undue amount of time in an interviewing process that can never work out as you’re looking for way more money than they’re willing to offer. Be ready to either give a value that is high in your range and say “but I’m flexible on this topic” or give a range “from X to Y”.
Other common questions you can expect here are:
“Why do you want to work here?”
“Have you checked our company values, what do you think of them?”
“Why do you want to leave your current job?”
“Have you got any experience with $thing-they-do?” (For instance remote work, or micro-services)
“How did you find this job posting?”
“What would make you decide not to take this job?”
“Tell us about yourself”
That last one, “tell us about yourself”, appears in many different variations throughout various interviewing stages. The real question is “please give us a one or two minute elevator pitch on why we should hire you”. Come with this pitch already prepared, at least the main ideas. You can take these from your cover letter, where you should go through a similar exercise. The interviewer wants to know what you could bring to the company, how well you would fit in with the team and ultimately be excited about the prospect of you joining. Hiring managers are humans, after all, and a recruiter that is excited with your application and your interview will positively affect the hiring manager and the rest of the interviewers. Highlight what you know, how well you would fit the team and that you’re a person that is easy to get along with. At the same time, also remember to be genuine.
A good recruiter will also have time for your questions at the end of the interview, if not before. Be ready to ask a couple of interesting questions that show that you’ve done your homework about the company and are interested in joining. Questions are often more important than the answers, as they reveal more about what you, as the candidate, are interested in. I often ask about topics pertaining to collaboration, the tech stack and aspects of the business model I don’t understand yet. Don’t ask questions just for the sake of it, but ask about what would really interest you about a potential future employer. End with a question like “I see on the job description that the next step is a test/an interview with X/other. Assuming you think I should move forward, when will I know if it’s going to happen?”. A great recruiter will tell you right away if you’re moving forward or not and will give you instructions (either on the call or with an email a few minutes after it).
It’s common advice to send a message thanking the interviewer after every interview. Personally, I don’t do this unless I have a question I want to ask or something to clarify/highlight. However, it’s still good advice, that Pedro also added in, so here it goes: After the recruiter interview, send the recruiter an email thanking them for their time (“this candidate is a nice person”), highlight something they said that was important to you (“this candidate paid attention to what I said”) and show yourself ready for the next steps (“this candidate is serious about this recruitment process”). Rinse and repeat after each of the next interviews, unless you don’t have access to their email addresses.
Going forward
This is the first part of what will likely be a 3-part blog post series, and all together a small eBook I wager 😂 Thanks again to my diligent reviewers Pedro & Eleni for helping round it out and fix some of my horrible comma skills. 💚
The other 2 parts I have in mind right now are about coding challenges and technical interviews. I might end up merging the 2 but seeing how much I’ve written about what I consider to be a lot more simple I think splitting them up will be just fine.
Remember, interviewing isn’t perfect and especially at the early stage you may get rejected for all kinds of reasons not even related to your own application – they might already have a candidate in the final stages whom they really like and close down the position. Keep going, you got this!
Back last year in June of 2022 I gave what’s one of my favorite talks (of myself) at the wonderful conference Code Beam A Coruña. It’s a talk where I take some of my interests – Basketball, fiction writing, game development and trading card games – and look what we can learn about software development from them.
The talk was a major hit at the conference, with way more people than normal coming up to me to thank me about it and to talk about it. The video has been online for 10 months, but I just saw it yesterday and I must admit to watching the full talk. I had forgotten quite some aspects of the talk, so it was educational – even for me. Normally, I never watch my talks back – this seemed worth it.
The audio quality isn’t the best, but I hope you might still enjoy it!
Let’s embark on a journey together – a journey in which we’ll weave together the realms of basketball, fiction writing, game development and trading card games to explore how these seemingly unrelated domains surprisingly intersect with the world of software development, offering fresh perspectives and insights.
Discover how concepts, strategies, and principles from these diverse domains can enhance your software development skills and creativity. Let’s celebrate the power of interdisciplinary thinking, revealing how diverse interests can invigorate your approach to software development.
Benchee 1.1.0 has finally hit hex.pm. After, well, almost 3 years. So, in this blog post we’ll dive into:
What are the changes
Why did it take so long, with some (significant) musings on Open Source and bugs as well as my approach to it
What does Benchee 1.1.0 Bring to the table
The star of the show certainly are the two new major features: reduction measurements and profiling! Then there is also a nasty bug that was squashed. Check out the Changelog for all.
Reduction Counting
Reductions joins execution time and memory consumption as the third measure Benchee can take. This one was kicked off way back when someone asked in our #benchee channel about adding this feature. What reductions are, is hard to explain. In short, it’s not very well defined but a “unit of work”. The BEAM uses them to keep track of how long a process has run. As the Beam Book puts it as follows:
BEAM solves this by keeping track of how long a process has been running. This is done by counting reductions. The term originally comes from the mathematical term beta-reduction used in lambda calculus.
The definition of a reduction in BEAM is not very specific, but we can see it as a small piece of work, which shouldn’t take too long. Each function call is counted as a reduction. BEAM does a test upon entry to each function to check whether the process has used up all its reductions or not. If there are reductions left the function is executed otherwise the process is suspended.
This can help you, as it’s not affected by system load so you could make assumptions in your CI about performance. It’s not 1:1 but it helps. Of course, check out Benchee’s docs about it. Biggest shout out goes to Devon for implementing it.
You can simply specify reduction_time and there you go:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
It’s worth noting that reduction counts will differ between different elixir and erlang versions – as we often noticed in our own CI setup.
Profile after benchmarking
Another feature that I’d never imagined having in Benchee, but thanks to community suggestions (and implementation!) it came to be. This one in particular was even suggested by José Valim himself – chatting with him he asked if there were plans to include something like this as his workflow would often be:
1. benchmark to see results
2. profile to find improvement opportunities
3. improve code
4. Start again at 1.
Makes perfect sense, I just never thought of it. So, you can now say profile_after: true or even specify a specific profiler + options.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We didn’t implement the profiling ourselves, but instead we rely on the builtin profiling tasks like this one. To make the feature fully compatible with hooks, I also had to send a small patch to elixir and so after_each hooks won’t work with profiling until it’s released. But, nobody uses hooks anyhow so, who cares? 😛
This feature made it in thanks to Pablo Costas, and his great work. I’m happy to highlight that not only did this contribution give us all a great Benchee feature, but also a friendship to boot. Oh, the wonders of Open Source. 💚
Measurement accuracy on Mac
Now to the least fun part about this release. There is a bugfix, a quite important one at that. Basically on Mac OS previous Benchee versions might report inaccurate results for very fast benchmarks (< 10 microseconds). There are many more musings in this issue, but basically we relied on the operating system clock returning times in a value that it can accurately measure in. Alas, OSX reports in nanoseconds but only has microsecond accuracy (leading to measurements being multiples of 1000). However, even the operating system clock reported nanosecond accuracy – so I even reported a bug on erlang/otp that was thankfully fixed in 22.2.
Fixing this was hard and stressful, which leads nicely into the next major section…
Why it took so long, perfectionism and open source
So, why did it take so long? I blogged earlier today about some of the things that held me back the past 1.5 years in “The Silence Between”. However, you can see that a lot of these features already landed in early 2020, so what gives?
The short answer is the bug above was hard to fix and I needed to fix it. The long answer is… well, long.
I think I could describe myself as a pragmatic perfectionist. I’m happy to implement an MVP, I constantly ask “Do we really need this?” or “Can we make this simpler and deliver it faster?”, but what I end up shipping I want to… well, almost need to be great for what we decided to ship. I don’t want to release with bugs, constant error notifications or barely anything tested. I can make lots of tradeoffs, as long as I decide on them like: Ok we’ll duplicate this code now, as we have no idea what a good abstraction might be and we don’t wanna lock ourselves in. But something misbehaving that I thought was sublime? Oh, the pain.
Why am I highlighting this? Well, Benchee reporting wrong resultsis frightening to me. Benchee has one core promise, and that promise is to measure your functions as accurately as possible. Also, in my opinion fixing critical bugs such as this one should have the highest priority. I can’t, for myself, justify working on Benchee while not working on that bug. I know, it’s not a great attitude and I should have released the features on main and just released the bug fix later. I do. But I felt like, all energy had to be spent on fixing that bug.
And working on that bug was hard. It’s a Mac only bug and I famously do not own or want to own a Mac. My partner owns one, but when I’m doing Open Source chances are she’s at her computer as well. And then, to investigate something like this, I need a couple of hours of interrupted time with no distractions on my mind as well. I might as well not even start otherwise. It certainly didn’t help that the bug randomly disappeared, when trying to look at it.
The problem that I did not have a Mac to fix this was finally solved when I started a new job, but then first the stress was too high and then my arms were injured (as mentioned in the other blog post). My arms finally got better and I had a good 4h+ to set aside to fix this bug. It can be kind of hard, to get that dedicated time but it’s absolutely needed for an intricate bug such as this one.
So, that’s the major reason it took so long. I mean, it involved finding a bug in Erlang itself. And, me working around that bug which is some code that well… was almost harder to write than the actual fix.
I would be amiss not to mention something else: It’s perfectly fine for Open Source project not to update! Sometimes, they are just done. Or the maintainers have more important things to do. I certainly consider Benchee “done” since 1.0 as it has all features I really wanted it to have. You see, reduction counting and profiler after are great features, but they are hardly essential.
Still, Benchee having a rather important bug for so long really made me feel guilty and bad. Even worse, because I didn’t fix the bug those great contributions from Devon and Pablo were never released. That’s another thing, that’s very important to me: Whoever takes the time to contribute should have a great experience and their contribution should be valued. The ultimate show of appreciation is releasing the feature they worked on is getting it released into people’s hands.
At times those negative feelings (“Oh no there is a bug” & “Oh no these great features lie around unreleased”) paradoxically lead me to stay away from Benchee even more since I felt bad about this state. Yes, it was only on mac and only affected benchmarks where individual function invocations took less than 10 microseconds. But still, that’s the perfectionist in me. This should be fixed within weeks, not 2.5 years. Most certainly, ready to ship features shouldn’t just chill on main for years. Release early, release often.
Anyhow, thanks for reading my musings on Open Source, responsibility, pragmatism and perfectionism. The bug is fixed now, the features are released and I’m happy. Who knows what’s next for Benchee.
What happened, why no new post in ~1.5 years? Well, the answer is quite simple: Life happened. First I was at a new job that was honestly quite stressful and took all my headspace, not leaving any space for blogging.
And then, I manged to injure my arms – how exactly I don’t know. It might have been a long time coming amplified by some unusually straining things I did that week. That was more than a year ago. I took 6 weeks off between jobs not doing anything hoping it will be better again soon. It wasn’t. Aside: Worst 6 week stay-cation of my life: at home, not programming, not writing & not playing games 😱 Of course, there was also Covid happening, welp.
Anyhow, I also did lots of physical therapy, saw specialists and did exercises every day for half an hour on a busy day to up to 4 hours+ on a free day. Good thing is, it was neither carpal nor cubital tunnel syndrome. I experimented with voice typing. Lots of stuff, this shit is scary.
I got a couple of breakthroughs – end of Summer 2021 my arms didn’t hurt more by the end of the week any more (as they did after a work week the entire time before). Before Christmas my pain got less to a degree where I could play games again.
And now? I still have varying degrees of pain, but now it’s mild pain and I feel like I can control it due to a variety of measures (braces, exercises, setup, it having gotten better). You gotta imagine, the first months of this I would sometimes get inexplicably strong pain jolting through my arm just because someone gave me an orange and I tried to hold it in my hand. Yeah, it was that bad.
So, I’m happy that I can do some gaming and some open source again. As well, as some writing. There are probably dozens of blog posts trapped in my head, half of which I have forgotten again. See, turns out I really do love software development. And so, while I was handicapped doing it or well was happy I could get to my day-to-day work but not in my free time, I thought about it – a lot.
So, let’s see how many posts I’ll manage to write and how much you’ll enjoy them.
A note on open source & responsibilities
With the last 1.5 years being mostly “I’m unable to do almost any open source or blogging”, I’m really happy that I changed my relationship to it. I used to feel guilty. I maintain big libraries, people depend on them. I need to fix bugs and have them be in great shape. That kinda feeling.
And well, I do still feel guilty. At the end of the day, I owe folks nothing. I provide free stuff. Take free stuff, fix free stuff and be happy. At the end of the day, my health and my life comes first. Doesn’t mean I don’t feel guilty sometimes or like I really need to fix something up, but it doesn’t eat me up and I’m fine. This would have been different
The expectation that maintainers are there to fix stuff whenever and face backlash when they don’t is what drives many people out of open source. I thankfully haven’t faced this backlash a lot, but it’s still a problem. Be better, everyone.
War in Ukraine
Now is a weird and arguably bad time to revive a tech blog. Russia’s unjust war of aggression on Ukraine, his threat of nukes and the unimaginable suffering of the Ukrainian people along with their bravery is on all our minds.
Well, I’m not sure if it is on yours but it for sure is on mine. This hits close to home for me. One of my closest friends was born in Ukraine. I have been to Ukraine for 3 years in a row pre-covid (2017-2019). I was planning to go again.
I gave talks at the wonderful Pivorak meetup in 2017 & 2019. Each time I had one of my closest friends with me and we had a little mini vacation in the wonderful city of Lviv that I want to visit again. Hell, I even have a favorite cafe in the city, I know the city and truly appreciate it. I’m not sure if calling many members of the Pivorak meetup (Anna, Oxana, Volodya, Anton…) “friends” is an exaggeration, but they’re definitely people that I’d excitedly run toward whenever I’d see them hug them and chat with them for as long as I could. And, I honestly don’t know if I’ll ever get that opportunity again. And… that is scary.
It was probably the best run ruby meetup I’ve ever seen, with curios, nice, humble and super active people. Hell, they even ran their own ruby learners workshop. They were shocked that people had forgotten the war in Ukraine and were afraid of Russia… little did we know.
I didn’t only see them in Lviv, some came to Berlin and I also saw them again at RubyC in Kyiv. Kyiv, where I walked across the Maidan square and past the memorials of the brave people who died during the Maidan protests, trying to pay my respect to each one of them.
So, with this background this is hard for me. I feel helpless as I can’t really help them. I don’t know what’s going to happen and what it will take for Putin to stop this war. Well, what I can do (and did!) and you can do as well is donate to support the Ukrainian people. If you’re reading this, you’re probably a software developer and have more dispensable income than most. Consider donating it through whichever means to organizations helping Ukraine. You can find donation links for instance here.
Sorry if this section is a bit more incoherent than usual, but I’m really lacking the words in any language to express how I feel.
So, with all that – why am I blogging/doing tech stuff? Honestly, I often don’t know how to help more. I’ll donate more, I’ll continue to speak up. I can’t think about the war 24/7, it’s hard and yes it’s privilege that I don’t have to think about it 24/7. As my current favorite author Brandon Sanderson said, we deal with these situations in our own way. He writes 5 extra novels in 2 years, I’ll focus some of my mind on open source and blogging. And also, I’ve been waiting for my arms to get better for so long – so I’ve been looking forward to this.
Before I’ll close this “short” interlude blog post, I have one more thing on my mind. Please do not confuse Putin & the Russian government with the Russian people.
I'm German. If you wanted to hate a country for what it's done, it's mine.
Yet I'm welcome everywhere. Esp. in Poland. I have many friends from there, in fact one of my very closest friends lives in Warsaw.
Please don't confuse Russia & Putin with the Russian people
It has been far too long, more than 3.5 years since the last edition of this benchmark. Well what to say? I almost had a new edition ready a year ago and then the job hunt got too intense and now the heat wave in Berlin delayed me. You don’t want your computer running at max capacity for an extended period, trust me.
Well, you aren’t here to hear about why there hasn’t been a new edition in so long, you’re here to read about the new edition! Most likely you’re here to look at graphs and see what’s the fastest ruby implementation out there. And I swear we’ll get to it but there’s some context to establish first. Of course, feel free to skip ahead if you just want the numbers.
Well, let’s do this!
What are we benchmarking?
We’re benchmarking Rubykon again, a Go AI written in Ruby using Monte Carlo Tree Search. It’s a fun project I wrote a couple of years back. Basically it does random playouts of Go games and sees what moves lead to a winning game building a tree with different game states and their win percentages to select the best move.
Why is this a good problem to benchmark? Performance matters. The more playouts we can do the better our AI plays because we have more data for our decisions. The benchmark we’re running starts its search from an empty 19×19 board (biggest “normal” board) and does 1000 full random playouts from there. We’ll measure how long that takes/how often we could do that in a minute. This also isn’t a micro benchmark, while remaining reasonable in size it looks at lots of different methods and access patterns.
Why is this a bad problem to benchmark? Most Ruby devs are probably interested in some kind of web application performance. This does no IO (which keeps the focus on ruby code execution, which is also good) and mainly deals with arrays. While we deal with collections all the time, rubykon also accesses a lot of array indexes all over, which isn’t really that common. It also barely deals with strings. Moreover, it does a whole lot of (pseudo-)random number generation which definitely isn’t a common occurrence. It also runs a relatively tight hot loop of “generate random valid move, play it, repeat until game over”, which should be friendly to JIT approaches.
What I want to say, this is an interesting problem to benchmark but it’s probably not representative of web application performance of the different ruby implementations. It is still a good indicator of where different ruby implementations rank performance wise.
It’s also important to note that this benchmark is single threaded – while it is a problem suited for parallelization I haven’t done so yet. Plus, single threaded applications are still typical for Ruby (due to the global interpreter lock in CRuby).
We’re also mainly interested in “warm” application performance i.e. giving them a bit of time to warm up and look at their peak performance. We’ll also look at the warmup times in a separate section though.
The competitors
Our competitors are ruby variants I could easily install on my machine and was interested in which brings us to:
CRuby 2.4.10
CRuby 2.5.8
CRuby 2.6.6
CRuby 2.7.1
CRuby 2.8.0-dev (b4b702dd4f from 2020-08-07) (this might end up being called Ruby 3 not 2.8)
truffleruby-1.0.0-rc16
truffleruby-20.1.0
jruby-9.1.17.0
jruby-9.2.11.1
All of those versions were current as of early August 2020. As usual doing all the benchmarking, graphing and writing has taken me some time so that truffleruby released a new version in the mean time, result shouldn’t differ much though.
CRuby (yes I still insist on calling it that vs. MRI) is mainly our base line as it’s the standard ruby interpreter. Versions that are capable of JITing (2.6+) will also be run with the –jit flag separately to show improvement (also referred to as MJIT).
TruffleRuby was our winner the last 2 times around. We’re running 20.1 and 1.0-rc16 (please don’t ask me why this specific version, it was in the matrix from when I originally redid this benchmarks a year ago). We’re also going to run both native and JVM mode for 20.1.
JRuby will be run “normally”, and with invokedynamic + server flag (denoted by “+ID”). We’re also gonna take a look at JDK 8 and JDK 14. For JDK 14 we’re also going to run it with a non default GC algorithm, falling back to the one used in JDK 8 as the new default is slower for this benchmark. Originally I also wanted to run with lots of different JVMs but as it stands I already recorded almost 40 different runs in total and the JVMs I tried didn’t show great differences so we’ll stick with the top performer of those I tried which is AdoptOpenJDK.
This is still running on the same Desktop PC that I did the first version of these benchmarks with – almost 5 years ago. In the meantime it was hit by a lot of those lovely intel security vulnerabilities though. It’s by no means a top machine any more.
The machine has 16 GB of RAM, runs Linux Mint 19.3 (based on Ubuntu 18.04 LTS) and most importantly an i7-4790 (3.6 GHz, 4 GHz boost) (which is more than 6 years old now).
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Timing wise I chose 5 minutes of warmup and 2 minutes of run time measurements. The (enormous) warmup time was mostly driven by behaviour observed in TruffleRuby where sometimes it would deoptimize even after a long warmup. So, I wanted to make sure everyone had all the time they needed to reach good “warm” performance.
Run Time Results
One more thing before we get to it: JRuby here ran on AdoptOpenJDK 8. Differences to AdoptOpenJDK 14 (and other JVMs) aren’t too big and would just clutter the graphs. We’ll take a brief look at them later.
If you want to take a look at all the data I gathered you can access the spreadsheet.
Iterations per Minute per Ruby implementation for running 1000 full playouts on a 19×19 board (higher is better).
Overall this looks more or less like the graphs from the last years:
CRuby is the baseline performance without any major jumps
JRuby with invokedynamic (+ID) gets a bit more than 2x the baseline performance of CRuby, invokedynamic itself makes it a lot faster (2x+)
TruffleRuby runs away with the win
What’s new though is the inclusion of the JIT option for CRuby which performs quite impressively and is only getting better. An 18% improvement on 2.6 goes up to 34% on 2.7 and tops out at 47% for 2.8 dev when looking at the JIT vs. non JIT run times of the same Ruby version. Looking at CRuby it’s also interesting that this time around “newer” CRuby performance is largely on par with not JITed JRuby performance.
The other thing that sticks out quite hugely are those big error bars on TruffleRuby 20. This is caused by some deoptimizations even after the long warmup. Portrayed here is a run where they weren’t as bad, even if they are worse performance was still top notch at 27 i/min overall though. It’s most likely a bug that these deoptimizations happen, you can check the corresponding issue. In the past the TruffleRuby always found a way to fix issues like this. So, the theoretical performance is a bit higher.
Another thing I like to look at is the relative speedup chart:
Speedup relative to CRuby 2.4.10 (baseline)
CRuby 2.4.10 was chosen as the “baseline” for this relative speedup chart mostly as a homage to Ruby 3×3 in which the goal was for Ruby 3 to be 3 times faster than Ruby 2.0. I can’t get Ruby < 2.4 to compile on my system easily any more and hence they are sadly missing here.
I’m pretty impressed with the JIT in Ruby 2.8: a speedup of over 60% is not to be scoffed at! So, as pointed out in the results above, I have ever rising hopes for it! JRuby (with invokedynamic) sits nice and comfortably at ~2.5x speedup which is a bit down from its 3x speedup in the older benchmarks. This might also be to the improved baseline of CRuby 2.4.10 versus the old CRuby 2.0 (check the old blog post for some numbers from then, not directly comparable though). TruffleRuby sits at the top thanks to the –jvm version with almost a 6x improvement. Perhaps more impressively it’s still 2.3 times faster than the fastest non TruffleRuby implementation. The difference between “native” and –jvm for TruffleRuby is also astounding and important to keep in mind should you do your own benchmarks.
What’s a bit baffling is that the performance trend for CRuby isn’t “always getting better” like I’m used to. The differences are rather small but looking at the small standard deviation (at most less than 1%) I’m rather sure of them. 2.5 is slower than 2.4, and 2.6 is faster than both 2.7 and 2.8.-dev. However, the “proper” order is established again when enabling the JIT.
If you’re rather interested in the data table you can still check out the spreadsheet for the full data, but here’s some of it inline:
Ruby
i/min
avg (s)
stddev %
relative speedup
2.4.10
5.61
10.69
0.86
1
2.5.8
5.16
11.63
0.27
0.919786096256684
2.6.6
6.61
9.08
0.42
1.17825311942959
2.6.6 –jit
7.8
7.69
0.59
1.3903743315508
2.7.1
6.45
9.3
0.25
1.14973262032086
2.7.1 –jit
8.64
6.95
0.29
1.54010695187166
2.8.0-dev
6.28
9.56
0.32
1.11942959001783
2.8.0-dev –jit
9.25
6.48
0.29
1.64884135472371
truffleruby-1.0.0-rc16
16.55
3.63
2.19
2.95008912655971
truffleruby-20.1.0
20.22
2.97
25.82
3.60427807486631
truffleruby-20.1.0 –jvm
33.32
1.8
19.01
5.93939393939394
jruby-9.1.17.0
6.52
9.21
0.63
1.16221033868093
jruby-9.1.17.0 +ID
14.27
4.2
0.29
2.54367201426025
jruby-9.2.11.1
6.33
9.49
0.54
1.1283422459893
jruby-9.2.11.1 +ID
13.85
4.33
0.44
2.46880570409982
Warmup
Seems the JITing approaches are winning throughout, however such performance isn’t free. Conceptually, a JIT looks at what parts of your code are run often and then tries to further optimize (and often specialize) these parts of the code. This makes it a whole lot faster, this process takes time and work though.
The benchmarking numbers presented above completely ignore the startup and warmup time. The common argument for this is that in long lived applications (like most web applications) we spend the majority of time in the warmed up/hot state. It’s different when talking about scripts we run as a one off. I visualized and described the different times to measure way more in another post.
Anyhow, lets get a better feeling for those warmup times, shall we? One of my favourite methods for doing so is graphing the first couple of run times as recorded (those are all during the warmup phase):
Run times as recorded by iteration number for a few select Ruby implementations. Lower is faster/better.
CRuby itself (without –jit) performs at a steady space, this is expected as no further optimizations are done and there’s also no cache or anything involved. Your first run is pretty much gonna be as fast as your last run. It’s impressive to see though that the –jit option is faster already in the first iteration and still getting better. What you can’t see in the graph, as it doesn’t contain enough run times and the difference is very small, is that the CRuby –jit option only reaches its peak performance around iteration 19 (going from ~6.7s to ~6.5s) which is quite surprising looking at how steady it seems before that.
TruffleRuby behaves in line with previous results. It has by far the longest warmup time, especially the JVM configuration which is in line with their presented pros and cons. The –jvm runtime configuration only becomes the fastest implementation by iteration 13! Then it’s faster by quite a bit though. It’s also noteworthy that for neither native nor JVM the time declines steadily. Sometimes subsequent iterations are slower which is likely due to the JIT trying hard to optimize something or having to deoptimize something. The random nature of Rubykon might play into this, as we might be hitting edge cases only at iteration 8 or so. While especially the first run time can be quite surprising, it’s noteworthy that during my years of doing these benchmarks I’ve seen TruffleRuby steadily improve its warmup time. As a datapoint, TruffleRuby 1.0.0-rc16 had its first 2 run times at 52 seconds and 25 seconds.
JRuby is very close to peak performance after one iteration already. Peak performance with invokedynamic is hit around iteration 7. It’s noteworthy that with invokedynamic even the first iteration is faster than CRuby “normal” and on par with the CRuby JIT implementation but in subsequent iterations gets much faster than them. The non invokedynamic version is very close to normal CRuby 2.8.0-dev performance almost the entire time, except for being slower in the first iteration.
For context it’s important to point out though that Rubykon is a relatively small application. Including the benchmarking library it’s not even 1200 lines of code long. It uses no external gems, it doesn’t even access the standard library. So all of the code is in these 1200 lines + the core Ruby classes (Array etc.) which is a far cry from a full blown Rails application. More code means more things to optimize and hence should lead to much longer warmup times than presented here.
JRuby/JVM musings
It might appear unfair that the results up there were run only with JDK 8. I can assure you, in my testing it sadly isn’t. I had hoped for some big performance jumps with the new JDK versions but I found no such thing. Indeed, it features the fastest version but only by a rather slim margin. It also requires switching up the GC algorithm as the new default performs worse at least for this benchmark.
Comparison JRuby with different options against AdoptOpenJDK 8 and 14
Performance is largely the same. JDK 14 is a bit faster when using both invokedynamic and falling back to the old garbage collector (+ParallelGC). Otherwise performance is worse. You can find out more in this issue. It’s curios though that JRuby 9.1 seems mostly faster than 9.2.
I got also quite excited at first looking at all the different new JVMs and thought I’d benchmark against them all, but it quickly became apparent that this was a typical case of “matrix explosion” and I really wanted for you all to also see these results unlike last year 😅 I gathered data for GraalVM and Java Standard Edition Reference Implementation in addition to AdoptOpenJDK but performance was largely the same and best at AdoptOpenJDK on my system for this benchmark. Again, these are in the spreadsheet.
I did one more try with OpenJ9 as it sounded promising. The results were so bad I didn’t even put them into the spreadsheet (~4 i/min without invokedynamic, ~1.5 i/min with invokedynamic). I can only imagine that either I’m missing a magic switch, OpenJ9 wasn’t built with a use case such as JRuby in mind or JRuby isn’t optimized to run on OpenJ9. Perhaps all of the above.
Final Thoughts
Alright, I hope this was interesting for y’all!
What did we learn? TruffleRuby still has the best “warm” performance by a mile, warmup is getting better but can still be tricky (–> unexpected slowdowns late into the process). The JIT for CRuby seems to get better continuously and has me a bit excited. CRuby performance has caught up to JRuby out of the box (without invokedynamic). JRuby with invokedynamic is still the second fastest Ruby implementation though.
It’s also interesting to see that every Ruby implementation has at least one switch (–jit, –jvm, invokedynamic) that significantly alters performance characteristics.
Please, also don’t forget the typical grain of salt: This is one benchmark, with one rather specific use case run on one machine. Results elsewhere might differ greatly.
What else is there? Promising to redo the benchmark next year would be something, but my experience tells me not to 😉
There’s an Enterprise version of GraalVM with supposedly good performance gains. Now, I won’t be spending money but you can evaluate it for free after registering. Well, if I ever manage to fix my Oracle login and get Oracle’s permission to publish the numbers I might (I’m fairly certain I can get that though 🙂 ). I also heard rumours of some CLI flags to try with TruffleRuby to get even better numbers 🤔
Finally, this benchmark has only looked at run times which is most often the most interesting value. However, there are other numbers that could prove interesting, such as memory consumption. These aren’t as easy to break down so neatly (or I don’t know how to). Showing the maximum amount of memory consumed during the measurement could be helpful though. As some people can tell you, with Ruby it can often be that you scale up your servers due to memory constraints not necessary CPU constraints.
I’d also be interested in how a new PC (planned purchase within a year!) affects these numbers.
So, there’s definitely some future work to be done here. Anything specific you want to see? Please let me know in the comments, via Twitter or however you like. Same goes for new graph types, mistakes I made or what not – I’m here to learn!