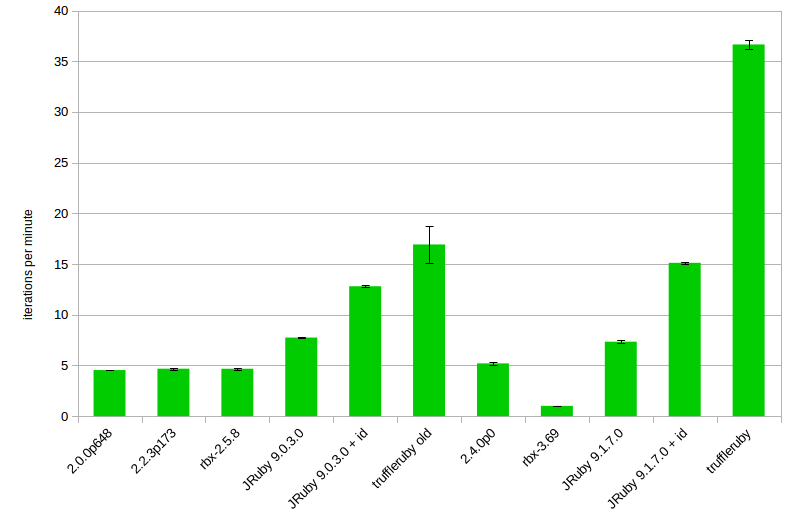
I’ve wanted to revisit “Tail Call Optimization in Elixir & Erlang – not as efficient and important as you probably think” (2016) for a while – so much so that I already revisited it once ~5 years ago to show off some benchee 1.0 features. As a reminder, in these the results were:
- body-recursive was fastest on input sizes of lists the size of 100k and 5M, but slower on the smallest input (10k list) and the biggest input (25M list). The difference either way was usually in the ~5% to 20% range.
- tail-recursive functions consumed significantly more memory
- we found that the order of the arguments for the tail-recusive function has a measurable impact on performance – namely doing the pattern match on the first argument of the recursive function was faster.
So, why should we revisit it again? Well, since then then JIT was introduced in OTP 24. And so, as our implementation changes, performance properties of functions may change over time. And, little spoiler, change they did.
To illustrate how performance changes across versions I wanted to show the performance across many different Elixir & OTP versions, I settled on the following ones:
- Elixir 1.6 @ OTP 21.3 – the oldest version I could get running without too much hassle
- Elixir 1.13 @ OTP 23.3 – the last OTP version before the JIT introduction
- Elixir 1.13 @ OTP 24.3 – the first major OTP version with the JIT (decided to use the newest minor though), using the same Elixir version as above so that the difference is up to OTP
- Elixir 1.16 @ OTP 26.2 – the most current Elixir & Erlang versions as of this writing
How do the performance characteristics change over time? Are we getting faster with time? Let’s find out! But first let’s discuss the benchmark.
The Benchmark
You can find the code in this repo. The implementations are still the same as last time. I dropped the “stdlib”/Enum.map part of the benchmark though as in the past it showed similar performance characteristics as the body-recursive implementation. It was also the only one not implemented “by hand”, more of a “gold-standard” to benchmark against. Hence it doesn’t hold too much value when discussing “which one of these simple hand-coded solutions is fastest?”.
It’s also worth nothing that this time the benchmarks are running on a new PC. Well, not new-new, it’s from 2020 but still a different one that the previous 2 benchmarks were run on.
System information
Operating System: Linux
CPU Information: AMD Ryzen 9 5900X 12-Core Processor
Number of Available Cores: 24
Available memory: 31.25 GB
As per usual, these benchmarks were run on an idle system with no other necessary applications running – not even a UI.
Without further ado the benchmarking script itself:
The script is fairly standard, except for long benchmarking times and a lot of inputs. The TAG environment variable has to do with the script that runs the benchmark across the different elixir & OTP versions. I might dig into that in a later blog post – but it’s just there to save them into different files and tag them with the respective version.
Also tail + order denotes the version that switched the order of the arguments around to pattern match on the first argument, as talked about before when recapping earlier results.
Results
As usual you can peruse the full benchmarking results in the HTML reports or the console output here:
Console Output of the benchmark
##### With input Small (10 Thousand) #####
Name ips average deviation median 99th %
tail +order (1.16.0-otp-26) 11.48 K 87.10 μs ±368.22% 72.35 μs 131.61 μs
tail (1.16.0-otp-26) 10.56 K 94.70 μs ±126.50% 79.80 μs 139.20 μs
tail +order (1.13.4-otp-24) 10.20 K 98.01 μs ±236.80% 84.80 μs 141.84 μs
tail (1.13.4-otp-24) 10.17 K 98.37 μs ±70.24% 85.55 μs 143.28 μs
body (1.16.0-otp-26) 8.61 K 116.19 μs ±18.37% 118.16 μs 167.50 μs
body (1.13.4-otp-24) 7.60 K 131.50 μs ±13.94% 129.71 μs 192.96 μs
tail +order (1.13.4-otp-23) 7.34 K 136.32 μs ±232.24% 120.61 μs 202.73 μs
body (1.13.4-otp-23) 6.51 K 153.55 μs ±9.75% 153.70 μs 165.62 μs
tail +order (1.6.6-otp-21) 6.36 K 157.14 μs ±175.28% 142.99 μs 240.49 μs
tail (1.13.4-otp-23) 6.25 K 159.92 μs ±116.12% 154.20 μs 253.37 μs
body (1.6.6-otp-21) 6.23 K 160.49 μs ±9.88% 159.88 μs 170.30 μs
tail (1.6.6-otp-21) 5.83 K 171.54 μs ±71.94% 158.44 μs 256.83 μs
Comparison:
tail +order (1.16.0-otp-26) 11.48 K
tail (1.16.0-otp-26) 10.56 K - 1.09x slower +7.60 μs
tail +order (1.13.4-otp-24) 10.20 K - 1.13x slower +10.91 μs
tail (1.13.4-otp-24) 10.17 K - 1.13x slower +11.27 μs
body (1.16.0-otp-26) 8.61 K - 1.33x slower +29.09 μs
body (1.13.4-otp-24) 7.60 K - 1.51x slower +44.40 μs
tail +order (1.13.4-otp-23) 7.34 K - 1.57x slower +49.22 μs
body (1.13.4-otp-23) 6.51 K - 1.76x slower +66.44 μs
tail +order (1.6.6-otp-21) 6.36 K - 1.80x slower +70.04 μs
tail (1.13.4-otp-23) 6.25 K - 1.84x slower +72.82 μs
body (1.6.6-otp-21) 6.23 K - 1.84x slower +73.38 μs
tail (1.6.6-otp-21) 5.83 K - 1.97x slower +84.44 μs
Extended statistics:
Name minimum maximum sample size mode
tail +order (1.16.0-otp-26) 68.68 μs 200466.90 μs 457.09 K 71.78 μs
tail (1.16.0-otp-26) 75.70 μs 64483.82 μs 420.52 K 79.35 μs, 79.36 μs
tail +order (1.13.4-otp-24) 79.22 μs 123986.92 μs 405.92 K 81.91 μs
tail (1.13.4-otp-24) 81.05 μs 41801.49 μs 404.37 K 82.62 μs
body (1.16.0-otp-26) 83.71 μs 5156.24 μs 343.07 K 86.39 μs
body (1.13.4-otp-24) 106.46 μs 5935.86 μs 302.92 K125.90 μs, 125.72 μs, 125
tail +order (1.13.4-otp-23) 106.66 μs 168040.73 μs 292.04 K 109.26 μs
body (1.13.4-otp-23) 139.84 μs 5164.72 μs 259.47 K 147.51 μs
tail +order (1.6.6-otp-21) 122.31 μs 101605.07 μs 253.46 K 138.40 μs
tail (1.13.4-otp-23) 115.74 μs 47040.19 μs 249.14 K 125.40 μs
body (1.6.6-otp-21) 109.67 μs 4938.61 μs 248.26 K 159.82 μs
tail (1.6.6-otp-21) 121.83 μs 40861.21 μs 232.24 K 157.72 μs
Memory usage statistics:
Name Memory usage
tail +order (1.16.0-otp-26) 223.98 KB
tail (1.16.0-otp-26) 223.98 KB - 1.00x memory usage +0 KB
tail +order (1.13.4-otp-24) 223.98 KB - 1.00x memory usage +0 KB
tail (1.13.4-otp-24) 223.98 KB - 1.00x memory usage +0 KB
body (1.16.0-otp-26) 156.25 KB - 0.70x memory usage -67.73438 KB
body (1.13.4-otp-24) 156.25 KB - 0.70x memory usage -67.73438 KB
tail +order (1.13.4-otp-23) 224.02 KB - 1.00x memory usage +0.0313 KB
body (1.13.4-otp-23) 156.25 KB - 0.70x memory usage -67.73438 KB
tail +order (1.6.6-otp-21) 224.03 KB - 1.00x memory usage +0.0469 KB
tail (1.13.4-otp-23) 224.02 KB - 1.00x memory usage +0.0313 KB
body (1.6.6-otp-21) 156.25 KB - 0.70x memory usage -67.73438 KB
tail (1.6.6-otp-21) 224.03 KB - 1.00x memory usage +0.0469 KB
**All measurements for memory usage were the same**
##### With input Middle (100 Thousand) #####
Name ips average deviation median 99th %
tail +order (1.16.0-otp-26) 823.46 1.21 ms ±33.74% 1.17 ms 2.88 ms
tail (1.16.0-otp-26) 765.87 1.31 ms ±32.35% 1.25 ms 2.99 ms
body (1.16.0-otp-26) 715.86 1.40 ms ±10.19% 1.35 ms 1.57 ms
body (1.13.4-otp-24) 690.92 1.45 ms ±10.57% 1.56 ms 1.64 ms
tail +order (1.13.4-otp-24) 636.45 1.57 ms ±42.91% 1.33 ms 3.45 ms
tail (1.13.4-otp-24) 629.78 1.59 ms ±42.61% 1.36 ms 3.45 ms
body (1.13.4-otp-23) 625.42 1.60 ms ±9.95% 1.68 ms 1.79 ms
body (1.6.6-otp-21) 589.10 1.70 ms ±9.69% 1.65 ms 1.92 ms
tail +order (1.6.6-otp-21) 534.56 1.87 ms ±25.30% 2.22 ms 2.44 ms
tail (1.13.4-otp-23) 514.88 1.94 ms ±23.90% 2.31 ms 2.47 ms
tail (1.6.6-otp-21) 514.64 1.94 ms ±24.51% 2.21 ms 2.71 ms
tail +order (1.13.4-otp-23) 513.89 1.95 ms ±23.73% 2.23 ms 2.47 ms
Comparison:
tail +order (1.16.0-otp-26) 823.46
tail (1.16.0-otp-26) 765.87 - 1.08x slower +0.0913 ms
body (1.16.0-otp-26) 715.86 - 1.15x slower +0.183 ms
body (1.13.4-otp-24) 690.92 - 1.19x slower +0.23 ms
tail +order (1.13.4-otp-24) 636.45 - 1.29x slower +0.36 ms
tail (1.13.4-otp-24) 629.78 - 1.31x slower +0.37 ms
body (1.13.4-otp-23) 625.42 - 1.32x slower +0.38 ms
body (1.6.6-otp-21) 589.10 - 1.40x slower +0.48 ms
tail +order (1.6.6-otp-21) 534.56 - 1.54x slower +0.66 ms
tail (1.13.4-otp-23) 514.88 - 1.60x slower +0.73 ms
tail (1.6.6-otp-21) 514.64 - 1.60x slower +0.73 ms
tail +order (1.13.4-otp-23) 513.89 - 1.60x slower +0.73 ms
Extended statistics:
Name minimum maximum sample size mode
tail +order (1.16.0-otp-26) 0.70 ms 5.88 ms 32.92 K 0.71 ms
tail (1.16.0-otp-26) 0.77 ms 5.91 ms 30.62 K 0.78 ms
body (1.16.0-otp-26) 0.90 ms 3.82 ms 28.62 K 1.51 ms, 1.28 ms
body (1.13.4-otp-24) 1.29 ms 3.77 ms 27.62 K 1.30 ms, 1.31 ms
tail +order (1.13.4-otp-24) 0.79 ms 6.21 ms 25.44 K1.32 ms, 1.32 ms, 1.32 ms
tail (1.13.4-otp-24) 0.80 ms 6.20 ms 25.18 K 1.36 ms
body (1.13.4-otp-23) 1.44 ms 4.77 ms 25.00 K 1.45 ms, 1.45 ms
body (1.6.6-otp-21) 1.39 ms 5.06 ms 23.55 K 1.64 ms
tail +order (1.6.6-otp-21) 1.28 ms 4.67 ms 21.37 K 1.42 ms
tail (1.13.4-otp-23) 1.43 ms 4.65 ms 20.59 K 1.44 ms, 1.44 ms
tail (1.6.6-otp-21) 1.11 ms 4.33 ms 20.58 K 1.40 ms
tail +order (1.13.4-otp-23) 1.26 ms 4.67 ms 20.55 K 1.52 ms
Memory usage statistics:
Name Memory usage
tail +order (1.16.0-otp-26) 2.90 MB
tail (1.16.0-otp-26) 2.90 MB - 1.00x memory usage +0 MB
body (1.16.0-otp-26) 1.53 MB - 0.53x memory usage -1.37144 MB
body (1.13.4-otp-24) 1.53 MB - 0.53x memory usage -1.37144 MB
tail +order (1.13.4-otp-24) 2.93 MB - 1.01x memory usage +0.0354 MB
tail (1.13.4-otp-24) 2.93 MB - 1.01x memory usage +0.0354 MB
body (1.13.4-otp-23) 1.53 MB - 0.53x memory usage -1.37144 MB
body (1.6.6-otp-21) 1.53 MB - 0.53x memory usage -1.37144 MB
tail +order (1.6.6-otp-21) 2.89 MB - 1.00x memory usage -0.00793 MB
tail (1.13.4-otp-23) 2.89 MB - 1.00x memory usage -0.01099 MB
tail (1.6.6-otp-21) 2.89 MB - 1.00x memory usage -0.00793 MB
tail +order (1.13.4-otp-23) 2.89 MB - 1.00x memory usage -0.01099 MB
**All measurements for memory usage were the same**
##### With input Big (1 Million) #####
Name ips average deviation median 99th %
tail (1.13.4-otp-24) 41.07 24.35 ms ±33.92% 24.44 ms 47.47 ms
tail +order (1.13.4-otp-24) 40.37 24.77 ms ±34.43% 24.40 ms 48.88 ms
tail +order (1.16.0-otp-26) 37.60 26.60 ms ±34.40% 24.86 ms 46.90 ms
tail (1.16.0-otp-26) 37.59 26.60 ms ±36.56% 24.57 ms 52.22 ms
tail +order (1.6.6-otp-21) 34.05 29.37 ms ±27.14% 30.79 ms 56.63 ms
tail (1.13.4-otp-23) 33.41 29.93 ms ±24.80% 31.17 ms 50.95 ms
tail +order (1.13.4-otp-23) 32.01 31.24 ms ±24.13% 32.78 ms 56.27 ms
tail (1.6.6-otp-21) 30.59 32.69 ms ±23.49% 33.78 ms 59.07 ms
body (1.13.4-otp-23) 26.93 37.13 ms ±4.54% 37.51 ms 39.63 ms
body (1.16.0-otp-26) 26.65 37.52 ms ±7.09% 38.36 ms 41.84 ms
body (1.6.6-otp-21) 26.32 38.00 ms ±4.56% 38.02 ms 43.01 ms
body (1.13.4-otp-24) 17.90 55.86 ms ±3.63% 55.74 ms 63.59 ms
Comparison:
tail (1.13.4-otp-24) 41.07
tail +order (1.13.4-otp-24) 40.37 - 1.02x slower +0.43 ms
tail +order (1.16.0-otp-26) 37.60 - 1.09x slower +2.25 ms
tail (1.16.0-otp-26) 37.59 - 1.09x slower +2.25 ms
tail +order (1.6.6-otp-21) 34.05 - 1.21x slower +5.02 ms
tail (1.13.4-otp-23) 33.41 - 1.23x slower +5.58 ms
tail +order (1.13.4-otp-23) 32.01 - 1.28x slower +6.89 ms
tail (1.6.6-otp-21) 30.59 - 1.34x slower +8.34 ms
body (1.13.4-otp-23) 26.93 - 1.53x slower +12.79 ms
body (1.16.0-otp-26) 26.65 - 1.54x slower +13.17 ms
body (1.6.6-otp-21) 26.32 - 1.56x slower +13.65 ms
body (1.13.4-otp-24) 17.90 - 2.29x slower +31.51 ms
Extended statistics:
Name minimum maximum sample size mode
tail (1.13.4-otp-24) 8.31 ms 68.32 ms 1.64 K None
tail +order (1.13.4-otp-24) 8.36 ms 72.16 ms 1.62 K 33.33 ms, 15.15 ms
tail +order (1.16.0-otp-26) 7.25 ms 61.46 ms 1.50 K 26.92 ms
tail (1.16.0-otp-26) 8.04 ms 56.17 ms 1.50 K None
tail +order (1.6.6-otp-21) 11.20 ms 69.86 ms 1.36 K 37.39 ms
tail (1.13.4-otp-23) 12.47 ms 60.67 ms 1.34 K None
tail +order (1.13.4-otp-23) 13.06 ms 74.43 ms 1.28 K 23.27 ms
tail (1.6.6-otp-21) 15.17 ms 73.09 ms 1.22 K None
body (1.13.4-otp-23) 20.90 ms 56.89 ms 1.08 K 38.11 ms
body (1.16.0-otp-26) 19.23 ms 57.76 ms 1.07 K None
body (1.6.6-otp-21) 19.81 ms 55.04 ms 1.05 K None
body (1.13.4-otp-24) 19.36 ms 72.21 ms 716 None
Memory usage statistics:
Name Memory usage
tail (1.13.4-otp-24) 26.95 MB
tail +order (1.13.4-otp-24) 26.95 MB - 1.00x memory usage +0 MB
tail +order (1.16.0-otp-26) 26.95 MB - 1.00x memory usage +0.00015 MB
tail (1.16.0-otp-26) 26.95 MB - 1.00x memory usage +0.00015 MB
tail +order (1.6.6-otp-21) 26.95 MB - 1.00x memory usage +0.00031 MB
tail (1.13.4-otp-23) 26.95 MB - 1.00x memory usage +0.00029 MB
tail +order (1.13.4-otp-23) 26.95 MB - 1.00x memory usage +0.00029 MB
tail (1.6.6-otp-21) 26.95 MB - 1.00x memory usage +0.00031 MB
body (1.13.4-otp-23) 15.26 MB - 0.57x memory usage -11.69537 MB
body (1.16.0-otp-26) 15.26 MB - 0.57x memory usage -11.69537 MB
body (1.6.6-otp-21) 15.26 MB - 0.57x memory usage -11.69537 MB
body (1.13.4-otp-24) 15.26 MB - 0.57x memory usage -11.69537 MB
**All measurements for memory usage were the same**
##### With input Giant (10 Million) #####
Name ips average deviation median 99th %
tail (1.16.0-otp-26) 8.59 116.36 ms ±24.44% 111.06 ms 297.27 ms
tail +order (1.16.0-otp-26) 8.07 123.89 ms ±39.11% 103.42 ms 313.82 ms
tail +order (1.13.4-otp-23) 5.15 194.07 ms ±28.32% 171.83 ms 385.56 ms
tail (1.13.4-otp-23) 5.05 197.91 ms ±26.21% 179.95 ms 368.95 ms
tail (1.13.4-otp-24) 4.82 207.47 ms ±31.62% 184.35 ms 444.05 ms
tail +order (1.13.4-otp-24) 4.77 209.59 ms ±31.01% 187.04 ms 441.28 ms
tail (1.6.6-otp-21) 4.76 210.30 ms ±26.31% 189.71 ms 406.29 ms
tail +order (1.6.6-otp-21) 4.15 240.89 ms ±28.46% 222.87 ms 462.93 ms
body (1.6.6-otp-21) 2.50 399.78 ms ±9.42% 397.69 ms 486.53 ms
body (1.13.4-otp-23) 2.50 399.88 ms ±7.58% 400.23 ms 471.07 ms
body (1.16.0-otp-26) 2.27 440.73 ms ±9.60% 445.77 ms 511.66 ms
body (1.13.4-otp-24) 2.10 476.77 ms ±7.72% 476.57 ms 526.09 ms
Comparison:
tail (1.16.0-otp-26) 8.59
tail +order (1.16.0-otp-26) 8.07 - 1.06x slower +7.53 ms
tail +order (1.13.4-otp-23) 5.15 - 1.67x slower +77.71 ms
tail (1.13.4-otp-23) 5.05 - 1.70x slower +81.55 ms
tail (1.13.4-otp-24) 4.82 - 1.78x slower +91.11 ms
tail +order (1.13.4-otp-24) 4.77 - 1.80x slower +93.23 ms
tail (1.6.6-otp-21) 4.76 - 1.81x slower +93.94 ms
tail +order (1.6.6-otp-21) 4.15 - 2.07x slower +124.53 ms
body (1.6.6-otp-21) 2.50 - 3.44x slower +283.42 ms
body (1.13.4-otp-23) 2.50 - 3.44x slower +283.52 ms
body (1.16.0-otp-26) 2.27 - 3.79x slower +324.37 ms
body (1.13.4-otp-24) 2.10 - 4.10x slower +360.41 ms
Extended statistics:
Name minimum maximum sample size mode
tail (1.16.0-otp-26) 81.09 ms 379.73 ms 343 None
tail +order (1.16.0-otp-26) 74.87 ms 407.68 ms 322 None
tail +order (1.13.4-otp-23) 129.96 ms 399.67 ms 206 None
tail (1.13.4-otp-23) 120.60 ms 429.31 ms 203 None
tail (1.13.4-otp-24) 85.42 ms 494.75 ms 193 None
tail +order (1.13.4-otp-24) 86.99 ms 477.82 ms 191 None
tail (1.6.6-otp-21) 131.60 ms 450.47 ms 190 224.04 ms
tail +order (1.6.6-otp-21) 124.69 ms 513.50 ms 166 None
body (1.6.6-otp-21) 207.61 ms 486.65 ms 100 None
body (1.13.4-otp-23) 200.16 ms 471.13 ms 100 None
body (1.16.0-otp-26) 202.63 ms 511.66 ms 91 None
body (1.13.4-otp-24) 200.17 ms 526.09 ms 84 None
Memory usage statistics:
Name Memory usage
tail (1.16.0-otp-26) 303.85 MB
tail +order (1.16.0-otp-26) 303.85 MB - 1.00x memory usage +0 MB
tail +order (1.13.4-otp-23) 303.79 MB - 1.00x memory usage -0.06104 MB
tail (1.13.4-otp-23) 303.79 MB - 1.00x memory usage -0.06104 MB
tail (1.13.4-otp-24) 301.64 MB - 0.99x memory usage -2.21191 MB
tail +order (1.13.4-otp-24) 301.64 MB - 0.99x memory usage -2.21191 MB
tail (1.6.6-otp-21) 303.77 MB - 1.00x memory usage -0.07690 MB
tail +order (1.6.6-otp-21) 303.77 MB - 1.00x memory usage -0.07690 MB
body (1.6.6-otp-21) 152.59 MB - 0.50x memory usage -151.25967 MB
body (1.13.4-otp-23) 152.59 MB - 0.50x memory usage -151.25967 MB
body (1.16.0-otp-26) 152.59 MB - 0.50x memory usage -151.25967 MB
body (1.13.4-otp-24) 152.59 MB - 0.50x memory usage -151.25967 MB
**All measurements for memory usage were the same**
##### With input Titanic (50 Million) #####
Name ips average deviation median 99th %
tail (1.13.4-otp-24) 0.85 1.18 s ±26.26% 1.11 s 2.00 s
tail +order (1.16.0-otp-26) 0.85 1.18 s ±28.67% 1.21 s 1.91 s
tail (1.16.0-otp-26) 0.84 1.18 s ±28.05% 1.18 s 1.97 s
tail +order (1.13.4-otp-24) 0.82 1.22 s ±27.20% 1.13 s 2.04 s
tail (1.13.4-otp-23) 0.79 1.26 s ±24.44% 1.25 s 1.88 s
tail +order (1.13.4-otp-23) 0.79 1.27 s ±22.64% 1.26 s 1.93 s
tail +order (1.6.6-otp-21) 0.76 1.32 s ±17.39% 1.37 s 1.83 s
tail (1.6.6-otp-21) 0.75 1.33 s ±18.22% 1.39 s 1.86 s
body (1.6.6-otp-21) 0.58 1.73 s ±15.01% 1.83 s 2.23 s
body (1.13.4-otp-23) 0.55 1.81 s ±19.33% 1.90 s 2.25 s
body (1.16.0-otp-26) 0.53 1.88 s ±16.13% 1.96 s 2.38 s
body (1.13.4-otp-24) 0.44 2.28 s ±17.61% 2.46 s 2.58 s
Comparison:
tail (1.13.4-otp-24) 0.85
tail +order (1.16.0-otp-26) 0.85 - 1.00x slower +0.00085 s
tail (1.16.0-otp-26) 0.84 - 1.01x slower +0.00803 s
tail +order (1.13.4-otp-24) 0.82 - 1.04x slower +0.0422 s
tail (1.13.4-otp-23) 0.79 - 1.07x slower +0.0821 s
tail +order (1.13.4-otp-23) 0.79 - 1.08x slower +0.0952 s
tail +order (1.6.6-otp-21) 0.76 - 1.12x slower +0.145 s
tail (1.6.6-otp-21) 0.75 - 1.13x slower +0.152 s
body (1.6.6-otp-21) 0.58 - 1.47x slower +0.55 s
body (1.13.4-otp-23) 0.55 - 1.54x slower +0.63 s
body (1.16.0-otp-26) 0.53 - 1.59x slower +0.70 s
body (1.13.4-otp-24) 0.44 - 1.94x slower +1.10 s
Extended statistics:
Name minimum maximum sample size mode
tail (1.13.4-otp-24) 0.84 s 2.00 s 34 None
tail +order (1.16.0-otp-26) 0.38 s 1.91 s 34 None
tail (1.16.0-otp-26) 0.41 s 1.97 s 34 None
tail +order (1.13.4-otp-24) 0.83 s 2.04 s 33 None
tail (1.13.4-otp-23) 0.73 s 1.88 s 32 None
tail +order (1.13.4-otp-23) 0.71 s 1.93 s 32 None
tail +order (1.6.6-otp-21) 0.87 s 1.83 s 31 None
tail (1.6.6-otp-21) 0.90 s 1.86 s 30 None
body (1.6.6-otp-21) 0.87 s 2.23 s 24 None
body (1.13.4-otp-23) 0.85 s 2.25 s 22 None
body (1.16.0-otp-26) 1.00 s 2.38 s 22 None
body (1.13.4-otp-24) 1.02 s 2.58 s 18 None
Memory usage statistics:
Name Memory usage
tail (1.13.4-otp-24) 1.49 GB
tail +order (1.16.0-otp-26) 1.49 GB - 1.00x memory usage -0.00085 GB
tail (1.16.0-otp-26) 1.49 GB - 1.00x memory usage -0.00085 GB
tail +order (1.13.4-otp-24) 1.49 GB - 1.00x memory usage +0 GB
tail (1.13.4-otp-23) 1.49 GB - 1.00x memory usage +0.00161 GB
tail +order (1.13.4-otp-23) 1.49 GB - 1.00x memory usage +0.00161 GB
tail +order (1.6.6-otp-21) 1.49 GB - 1.00x memory usage +0.00151 GB
tail (1.6.6-otp-21) 1.49 GB - 1.00x memory usage +0.00151 GB
body (1.6.6-otp-21) 0.75 GB - 0.50x memory usage -0.74222 GB
body (1.13.4-otp-23) 0.75 GB - 0.50x memory usage -0.74222 GB
body (1.16.0-otp-26) 0.75 GB - 0.50x memory usage -0.74222 GB
body (1.13.4-otp-24) 0.75 GB - 0.50x memory usage -0.74222 GB
So, what are our key findings?
Tail-Recursive Functions with Elixir 1.16 @ OTP 26.2 are fastest
For all but one input elixir 1.16 @ OTP 26.2 is the fastest implementation or virtually tied with the fastest implementation. It’s great to know that our most recent version brings us some speed goodies!
Is that the impact of the JIT you may ask? It can certainly seem so – when we’re looking at the list with 10 000 elements as input we see that even the slowest JIT implementation is faster than the fastest non-JIT implementation (remember, the JIT was introduced in OTP 24):
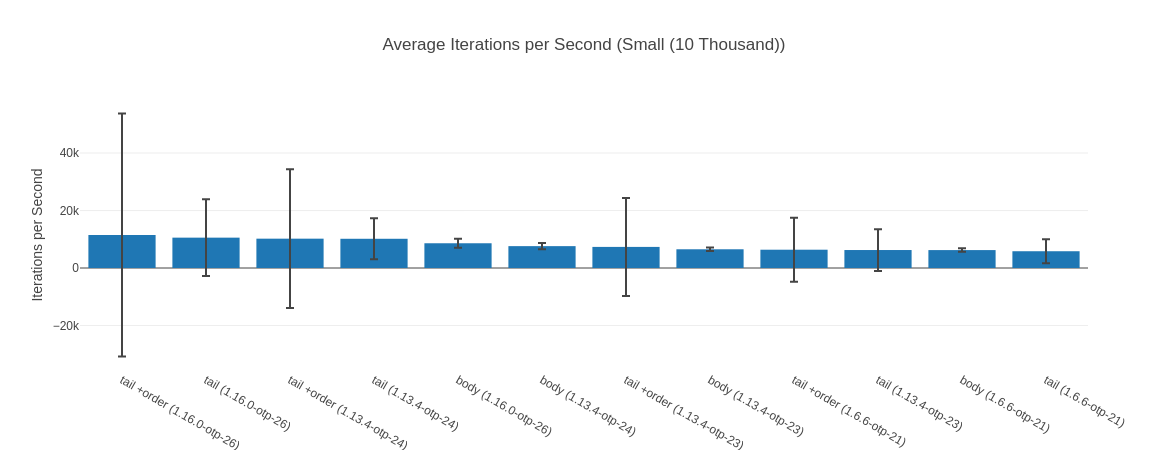
Table with more detailed data
| Name | Iterations per Second | Average | Deviation | Median | Mode | Minimum | Maximum | Sample size |
|---|---|---|---|---|---|---|---|---|
| tail +order (1.16.0-otp-26) | 11.48 K | 87.10 μs | ±368.22% | 72.35 μs | 71.78 μs | 68.68 μs | 200466.90 μs | 457086 |
| tail (1.16.0-otp-26) | 10.56 K | 94.70 μs | ±126.50% | 79.80 μs | 79.35 μs, 79.36 μs | 75.70 μs | 64483.82 μs | 420519 |
| tail +order (1.13.4-otp-24) | 10.20 K | 98.01 μs | ±236.80% | 84.80 μs | 81.91 μs | 79.22 μs | 123986.92 μs | 405920 |
| tail (1.13.4-otp-24) | 10.17 K | 98.37 μs | ±70.24% | 85.55 μs | 82.62 μs | 81.05 μs | 41801.49 μs | 404374 |
| body (1.16.0-otp-26) | 8.61 K | 116.19 μs | ±18.37% | 118.16 μs | 86.39 μs | 83.71 μs | 5156.24 μs | 343072 |
| body (1.13.4-otp-24) | 7.60 K | 131.50 μs | ±13.94% | 129.71 μs | 125.90 μs, 125.72 μs, 125.91 μs | 106.46 μs | 5935.86 μs | 302924 |
| tail +order (1.13.4-otp-23) | 7.34 K | 136.32 μs | ±232.24% | 120.61 μs | 109.26 μs | 106.66 μs | 168040.73 μs | 292044 |
| body (1.13.4-otp-23) | 6.51 K | 153.55 μs | ±9.75% | 153.70 μs | 147.51 μs | 139.84 μs | 5164.72 μs | 259470 |
| tail +order (1.6.6-otp-21) | 6.36 K | 157.14 μs | ±175.28% | 142.99 μs | 138.40 μs | 122.31 μs | 101605.07 μs | 253459 |
| tail (1.13.4-otp-23) | 6.25 K | 159.92 μs | ±116.12% | 154.20 μs | 125.40 μs | 115.74 μs | 47040.19 μs | 249144 |
| body (1.6.6-otp-21) | 6.23 K | 160.49 μs | ±9.88% | 159.88 μs | 159.82 μs | 109.67 μs | 4938.61 μs | 248259 |
| tail (1.6.6-otp-21) | 5.83 K | 171.54 μs | ±71.94% | 158.44 μs | 157.72 μs | 121.83 μs | 40861.21 μs | 232243 |
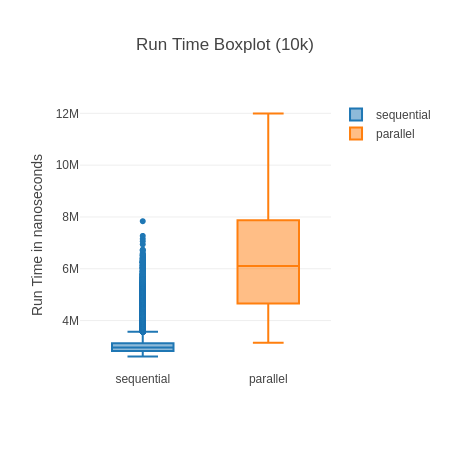
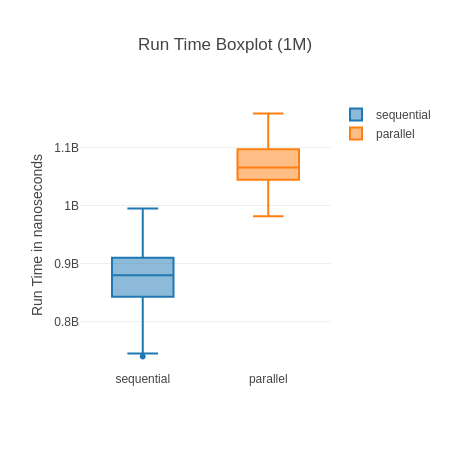
You can see the standard deviation here can be quite high, which is “thanks” to a few outliers that make the boxplot almost unreadable. Noise from Garbage Collection is often a bit of a problem with micro-benchmarks, but the results are stable and the sample size big enough. Here is a highly zoomed in boxplot to make it readable:
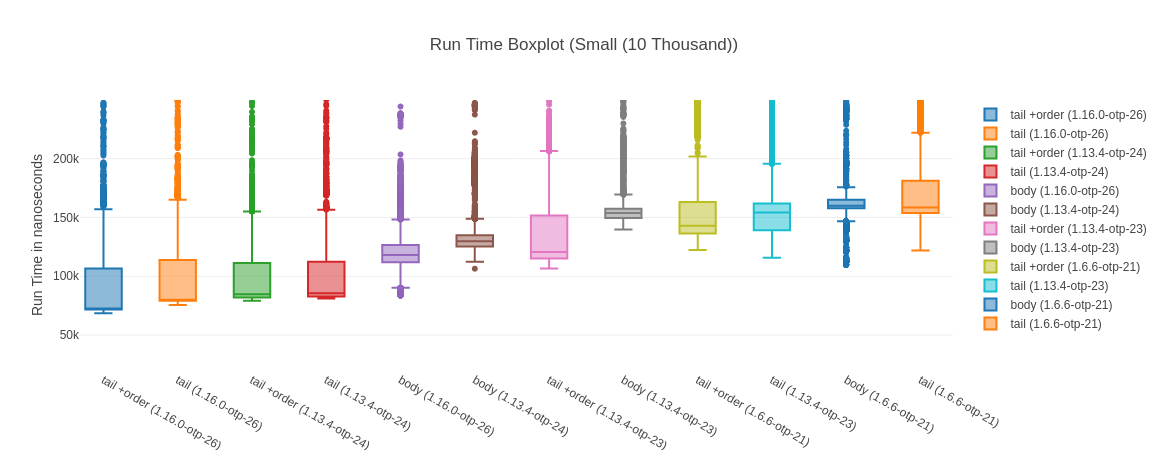
What’s really impressive to me is that the fastest version is 57% faster than the fastest non JIT version (tail +order (1.16.0-otp-26) vs. tail +order (1.13.4-otp-23)). Of course, this is a very specific benchmark and may not be indicative of overall performance gains – it’s impressive nonetheless. The other good sign is that we seem to be continuing to improve, as our current best version is 13% faster than anything available on our other most recent platform (1.13 @ OTP 24.3).
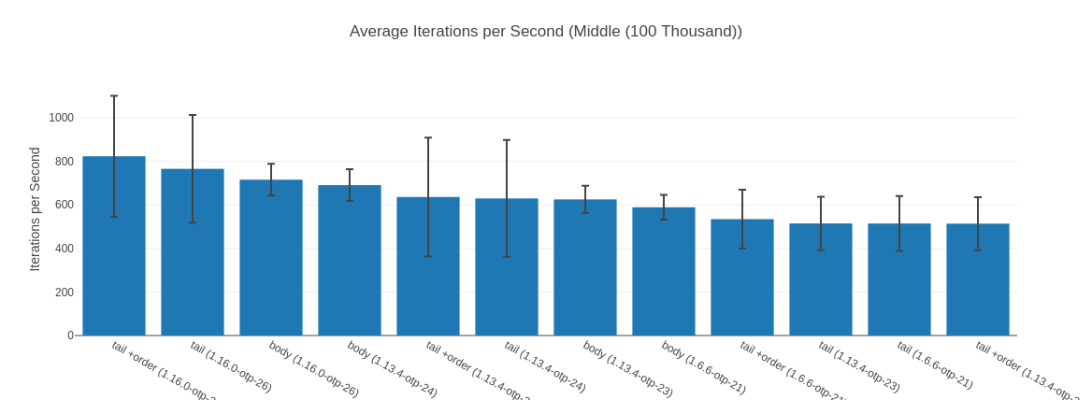
The performance uplift of Elixir 1.16 running on OTP 26.2 is even more impressive when we look at the input list of 100k elements – where all its map implementations take the 3 top spots:
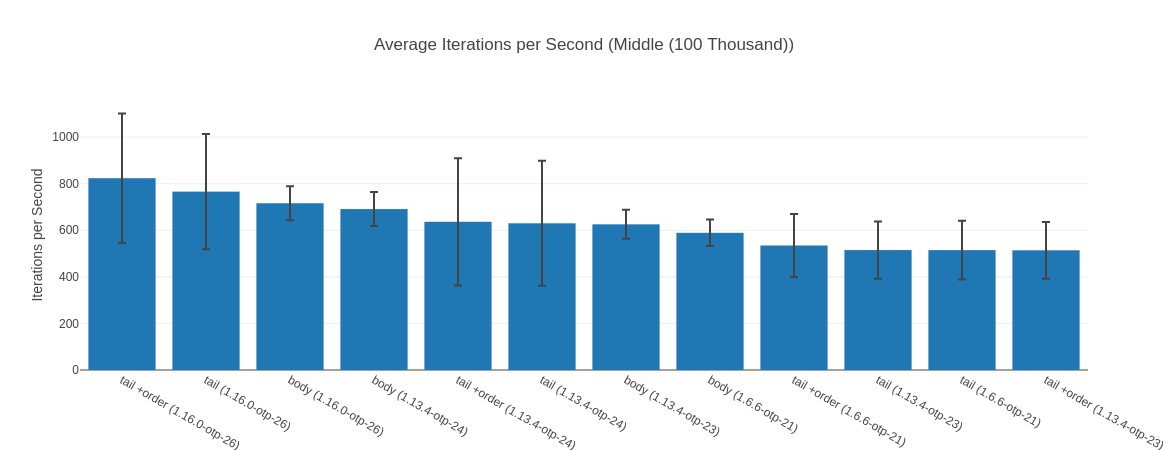
Table with more detailed data
| Name | Iterations per Second | Average | Deviation | Median | Mode | Minimum | Maximum | Sample size |
|---|---|---|---|---|---|---|---|---|
| tail +order (1.16.0-otp-26) | 823.46 | 1.21 ms | ±33.74% | 1.17 ms | 0.71 ms | 0.70 ms | 5.88 ms | 32921 |
| tail (1.16.0-otp-26) | 765.87 | 1.31 ms | ±32.35% | 1.25 ms | 0.78 ms | 0.77 ms | 5.91 ms | 30619 |
| body (1.16.0-otp-26) | 715.86 | 1.40 ms | ±10.19% | 1.35 ms | 1.51 ms, 1.28 ms | 0.90 ms | 3.82 ms | 28623 |
| body (1.13.4-otp-24) | 690.92 | 1.45 ms | ±10.57% | 1.56 ms | 1.30 ms, 1.31 ms | 1.29 ms | 3.77 ms | 27623 |
| tail +order (1.13.4-otp-24) | 636.45 | 1.57 ms | ±42.91% | 1.33 ms | 1.32 ms, 1.32 ms, 1.32 ms, 1.32 ms, 1.32 ms, 1.32 ms | 0.79 ms | 6.21 ms | 25444 |
| tail (1.13.4-otp-24) | 629.78 | 1.59 ms | ±42.61% | 1.36 ms | 1.36 ms | 0.80 ms | 6.20 ms | 25178 |
| body (1.13.4-otp-23) | 625.42 | 1.60 ms | ±9.95% | 1.68 ms | 1.45 ms, 1.45 ms | 1.44 ms | 4.77 ms | 25004 |
| body (1.6.6-otp-21) | 589.10 | 1.70 ms | ±9.69% | 1.65 ms | 1.64 ms | 1.39 ms | 5.06 ms | 23553 |
| tail +order (1.6.6-otp-21) | 534.56 | 1.87 ms | ±25.30% | 2.22 ms | 1.42 ms | 1.28 ms | 4.67 ms | 21373 |
| tail (1.13.4-otp-23) | 514.88 | 1.94 ms | ±23.90% | 2.31 ms | 1.44 ms, 1.44 ms | 1.43 ms | 4.65 ms | 20586 |
| tail (1.6.6-otp-21) | 514.64 | 1.94 ms | ±24.51% | 2.21 ms | 1.40 ms | 1.11 ms | 4.33 ms | 20577 |
| tail +order (1.13.4-otp-23) | 513.89 | 1.95 ms | ±23.73% | 2.23 ms | 1.52 ms | 1.26 ms | 4.67 ms | 20547 |
Here the speedup of “fastest JIT vs. fastest non JIT” is still a great 40%. Interestingly here though, for all versions except for Elixir 1.16.0 on OTP 26.2 the body-recursive functions are faster than their tail-recursive counter parts. Hold that thought for later, let’s first take a look a weird outlier – the input list with 1 Million elements.
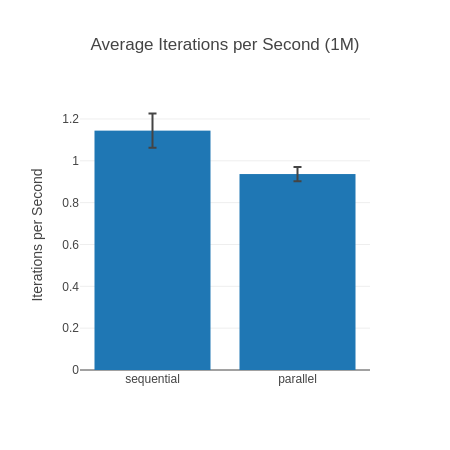
The Outlier Input – 1 Million
So, why is that the outlier? Well, here Elixir 1.13 on OTP 24.3 is faster than Elixir 1.16 on OTP 26.2! Maybe we just got unlucky you may think, but I have reproduced this result over many different runs of this benchmark. The lead also goes away again with an input list of 10 Million. Now, you may say “Tobi, we shouldn’t be dealing with lists of 1 Million and up elements anyhow” and I’d agree with you. Humor me though, as I find it fascinating what a huge impact inputs can have as well as how “random” they are. At 100k and 10 Million our Elixir 1.16 is fastest, but somehow for 1 Million it isn’t? I have no idea why, but it seems legit.
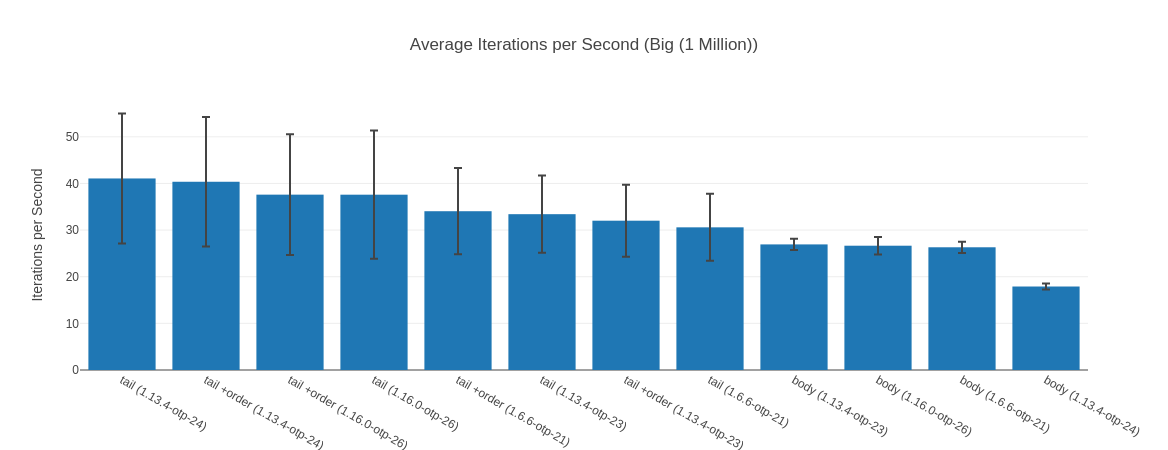
Table with more data
| Name | Iterations per Second | Average | Deviation | Median | Mode | Minimum | Maximum | Sample size |
|---|---|---|---|---|---|---|---|---|
| tail (1.13.4-otp-24) | 41.07 | 24.35 ms | ±33.92% | 24.44 ms | none | 8.31 ms | 68.32 ms | 1643 |
| tail +order (1.13.4-otp-24) | 40.37 | 24.77 ms | ±34.43% | 24.40 ms | 33.33 ms, 15.15 ms | 8.36 ms | 72.16 ms | 1615 |
| tail +order (1.16.0-otp-26) | 37.60 | 26.60 ms | ±34.40% | 24.86 ms | 26.92 ms | 7.25 ms | 61.46 ms | 1504 |
| tail (1.16.0-otp-26) | 37.59 | 26.60 ms | ±36.56% | 24.57 ms | none | 8.04 ms | 56.17 ms | 1503 |
| tail +order (1.6.6-otp-21) | 34.05 | 29.37 ms | ±27.14% | 30.79 ms | 37.39 ms | 11.20 ms | 69.86 ms | 1362 |
| tail (1.13.4-otp-23) | 33.41 | 29.93 ms | ±24.80% | 31.17 ms | none | 12.47 ms | 60.67 ms | 1336 |
| tail +order (1.13.4-otp-23) | 32.01 | 31.24 ms | ±24.13% | 32.78 ms | 23.27 ms | 13.06 ms | 74.43 ms | 1280 |
| tail (1.6.6-otp-21) | 30.59 | 32.69 ms | ±23.49% | 33.78 ms | none | 15.17 ms | 73.09 ms | 1224 |
| body (1.13.4-otp-23) | 26.93 | 37.13 ms | ±4.54% | 37.51 ms | 38.11 ms | 20.90 ms | 56.89 ms | 1077 |
| body (1.16.0-otp-26) | 26.65 | 37.52 ms | ±7.09% | 38.36 ms | none | 19.23 ms | 57.76 ms | 1066 |
| body (1.6.6-otp-21) | 26.32 | 38.00 ms | ±4.56% | 38.02 ms | none | 19.81 ms | 55.04 ms | 1052 |
| body (1.13.4-otp-24) | 17.90 | 55.86 ms | ±3.63% | 55.74 ms | none | 19.36 ms | 72.21 ms | 716 |
Before we dig in, it’s interesting to notice that at the 1 Million inputs mark, the body-recursive functions together occupy the last 4 spots of our ranking. It stays like this for all bigger inputs.
When I look at a result that is “weird” to me I usually look at a bunch of other statistical values: 99th%, median, standard deviation, maximum etc. to see if maybe there were some weird outliers here. Specifically I’m checking whether the medians roughly line up with the averages in their ordering – which they do here. Everything seems fine here.
The next thing I’m looking are the raw recorded run times (in order) as well as their general distribution. While looking at those you can notice some interesting behavior. While both elixir 1.13 @ OTP 24.3 solutions have a more or less steady pattern to their run times, their elixir 1.16 @ OTP 26.2 counter parts seem to experience a noticeable slow down towards the last ~15% of their measurement time. Let’s look at 2 examples for the the tail +order variants:
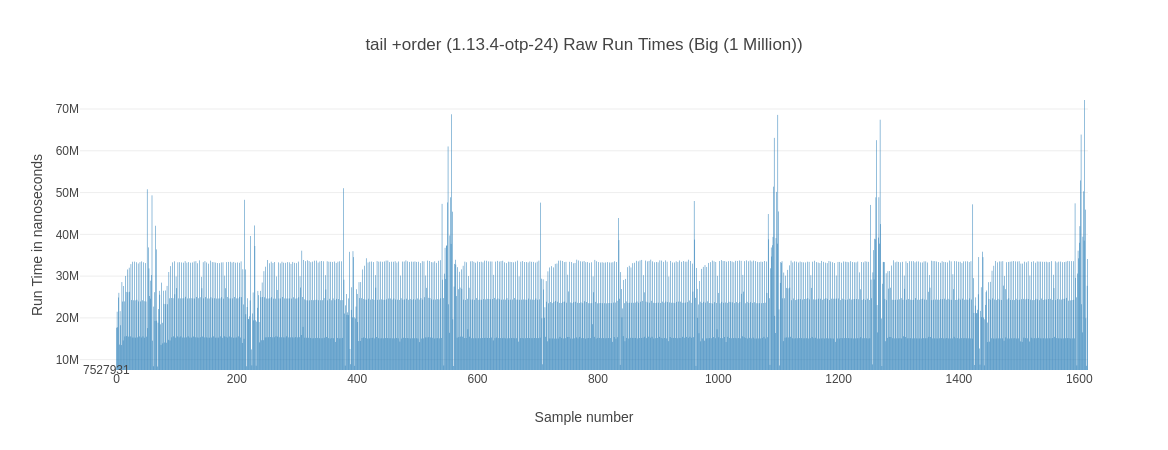
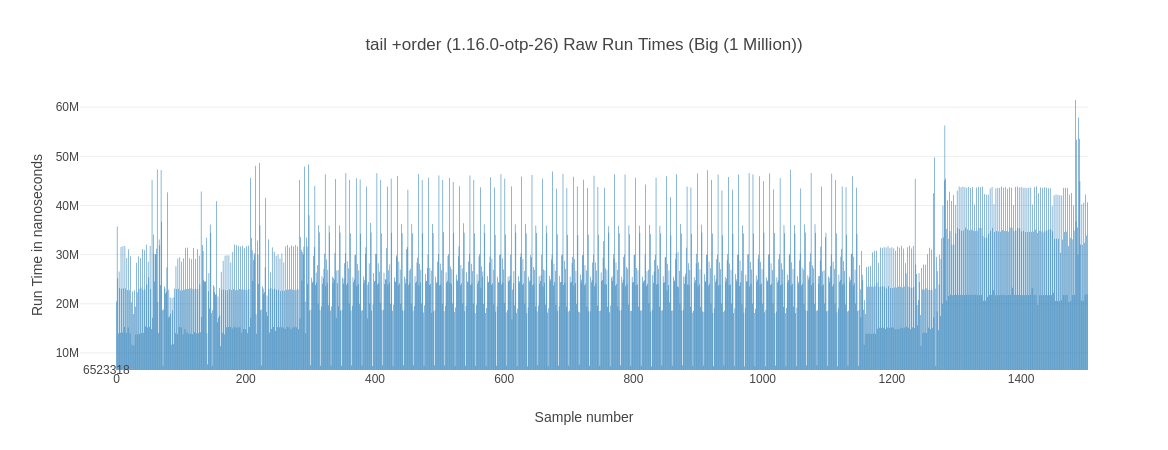
Why is this happening? I don’t know – you could blame it on on some background job or something kicking in but then it wouldn’t be consistent across tail and tail +order for the elixir 1.16 variant. While we’re looking at these graphs, what about the bod-recursive cousin?
Less Deviation for Body-Recursive Functions
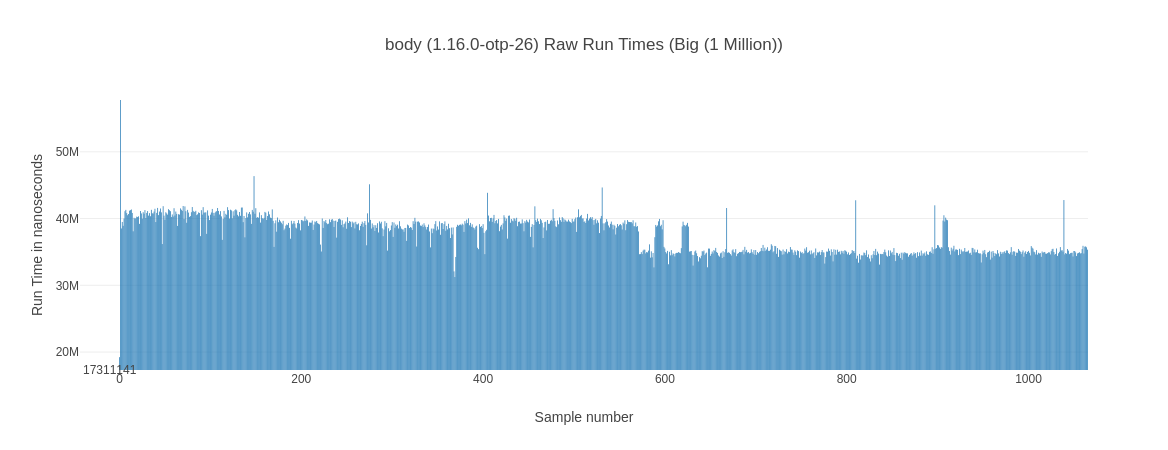
The body-recursive version looks a lot smoother and less jittery. This is something you can observe across all inputs – as indicated by the much lower standard-deviation of body-recursive implementations.
Memory Consumption
The memory consumption story is much less interesting – body-recursive functions consume less memory and by quite the margin! ~50% of the tail-recursive functions for all but our smallest input size – there it’s still 70%.
This might also be one of the key to seeing less jittery run times – less memory means less garbage produced means fewer garbage collection runs necessary.
A 60%+ lead – the 10 Million Input
What I found interesting looking at the results is that for our 10 Million input elixir 1.16 @ OTP 26 is 67% faster than the next fastest implementation. Which is a huge difference.
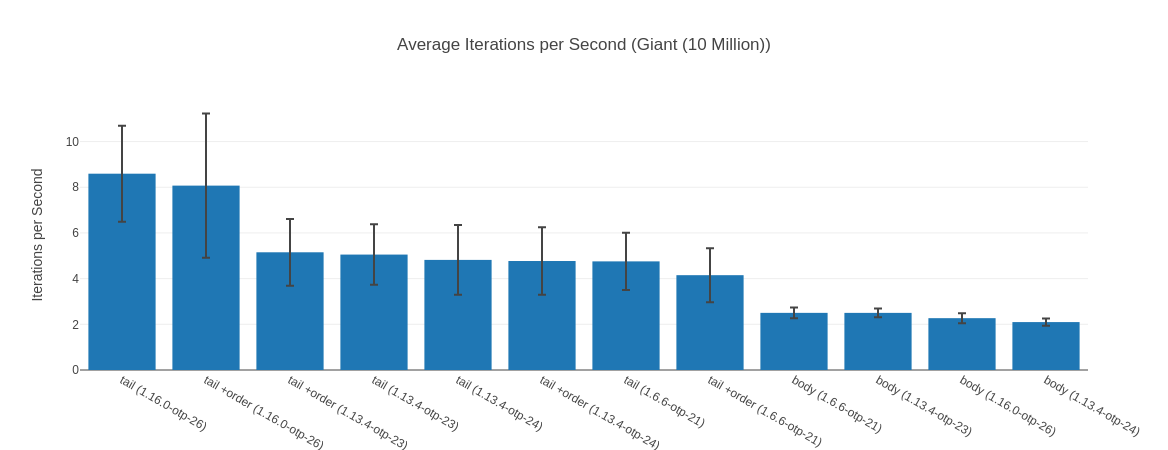
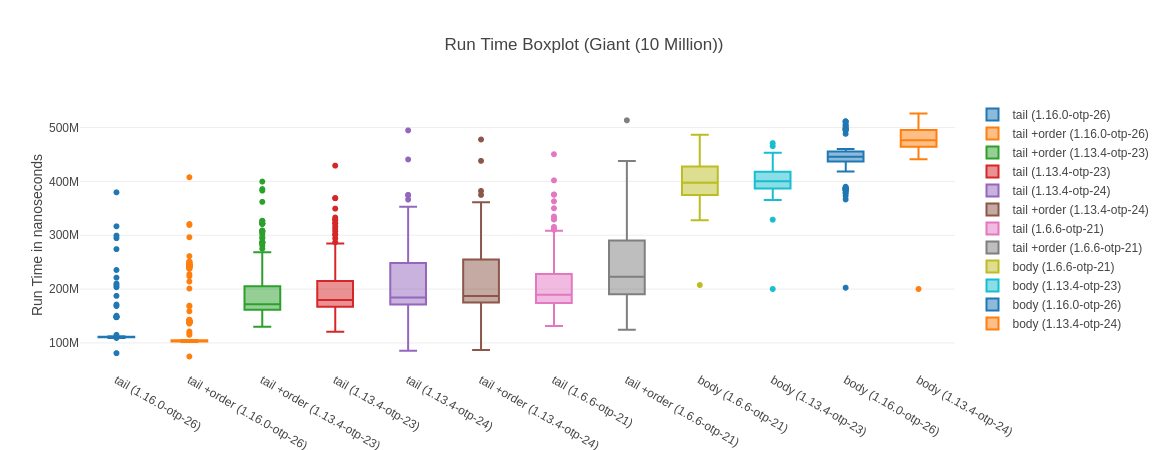
Table with more data
| Name | Iterations per Second | Average | Deviation | Median | Mode | Minimum | Maximum | Sample size |
|---|---|---|---|---|---|---|---|---|
| tail (1.16.0-otp-26) | 8.59 | 116.36 ms | ±24.44% | 111.06 ms | none | 81.09 ms | 379.73 ms | 343 |
| tail +order (1.16.0-otp-26) | 8.07 | 123.89 ms | ±39.11% | 103.42 ms | none | 74.87 ms | 407.68 ms | 322 |
| tail +order (1.13.4-otp-23) | 5.15 | 194.07 ms | ±28.32% | 171.83 ms | none | 129.96 ms | 399.67 ms | 206 |
| tail (1.13.4-otp-23) | 5.05 | 197.91 ms | ±26.21% | 179.95 ms | none | 120.60 ms | 429.31 ms | 203 |
| tail (1.13.4-otp-24) | 4.82 | 207.47 ms | ±31.62% | 184.35 ms | none | 85.42 ms | 494.75 ms | 193 |
| tail +order (1.13.4-otp-24) | 4.77 | 209.59 ms | ±31.01% | 187.04 ms | none | 86.99 ms | 477.82 ms | 191 |
| tail (1.6.6-otp-21) | 4.76 | 210.30 ms | ±26.31% | 189.71 ms | 224.04 ms | 131.60 ms | 450.47 ms | 190 |
| tail +order (1.6.6-otp-21) | 4.15 | 240.89 ms | ±28.46% | 222.87 ms | none | 124.69 ms | 513.50 ms | 166 |
| body (1.6.6-otp-21) | 2.50 | 399.78 ms | ±9.42% | 397.69 ms | none | 207.61 ms | 486.65 ms | 100 |
| body (1.13.4-otp-23) | 2.50 | 399.88 ms | ±7.58% | 400.23 ms | none | 200.16 ms | 471.13 ms | 100 |
| body (1.16.0-otp-26) | 2.27 | 440.73 ms | ±9.60% | 445.77 ms | none | 202.63 ms | 511.66 ms | 91 |
| body (1.13.4-otp-24) | 2.10 | 476.77 ms | ±7.72% | 476.57 ms | none | 200.17 ms | 526.09 ms | 84 |
We also see that the tail-recursive solution here is almost 4 times as fast as the body-recursive version. Somewhat interestingly the version without the argument order switch seems faster here (but not by much). You can also see that the median is (considerably) in favor of tail +order against its just tail counter part.
Let’s take another look at our new found friend – the raw run times chart:
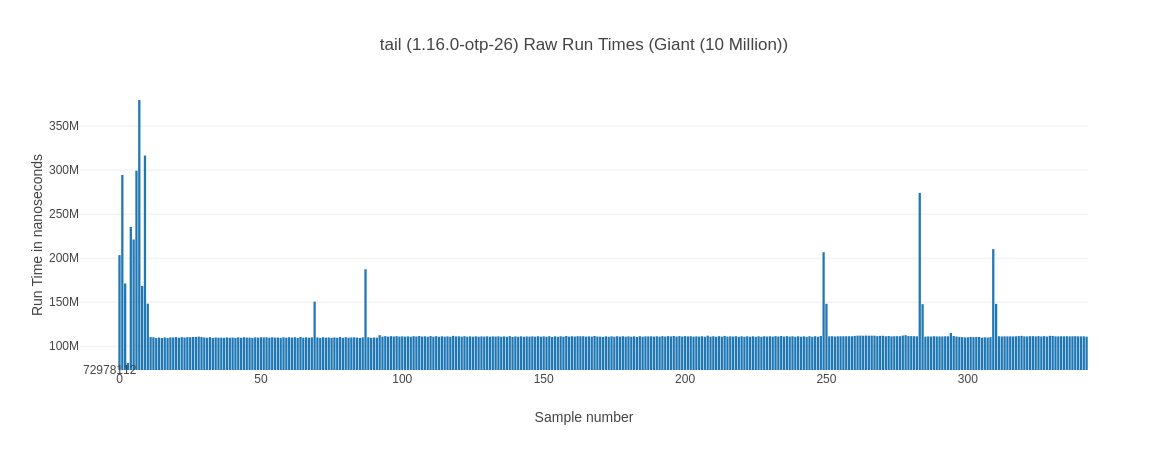
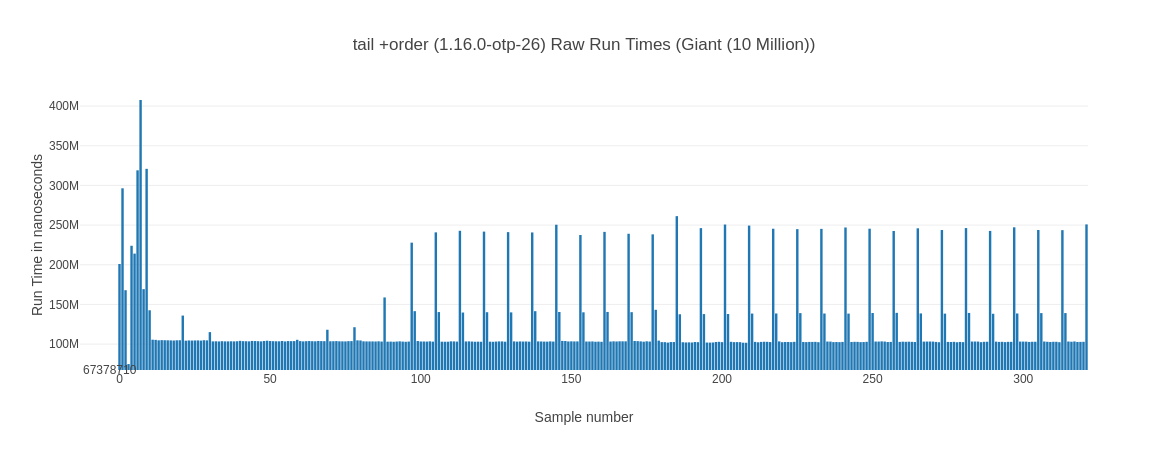
We can clearly see that the tail +order version goes into a repeating pattern of taking much longer every couple of runs while the tail version is (mostly) stable. That explains the lower average while it has a higher median for the tail version. It is faster on average by being more consistent – so while its median is slightly worse it is on average faster as it doesn’t exhibit these spikes. Why is this happening? I don’t know, except that I know I’ve seen it more than once.
The body-recursive to tail-recursive reversal
As you may remember from the intro, this journey once began with “Tail Call Optimization in Elixir & Erlang – not as efficient and important as you probably think” – claiming that body-recursive version was faster than the tail-recursive version. The last revision showed some difference in what function was faster based on what input was used.
And now? For Elixir 1.16 on OTP 26.2 the tail-recursive functions are faster than their body-recursive counter part on all tested inputs! How different depends on the input size – from just 15% to almost 400% we’ve seen it all.
This is also a “fairly recent” development – for instance for our 100k input for Elixir 1.13@OTP 24 the body-recursive function is the fastest.
Naturally that still doesn’t mean everything should be tail-recursive: This is one benchmark with list sizes you may rarely see. Memory consumption and variance are also points to consider. Also let’s remember a quote from “The Seven Myths of Erlang Performance” about this:
It is generally not possible to predict whether the tail-recursive or the body-recursive version will be faster. Therefore, use the version that makes your code cleaner (hint: it is usually the body-recursive version).
And of course, some use cases absolutely need a tail-recursive function (such as Genservers).
Finishing Up
So, what have we discovered? On our newest Elixir and Erlang versions tail-recursive functions shine more than they did before – outperforming the competition. We have seen some impressive performance improvements over time, presumably thanks to the JIT – and we seem to be getting even more performance improvements.
As always, run your own benchmarks – don’t trust some old post on the Internet saying one thing is faster than another. Your compiler, your run time – things may have changed.
Lastly, I’m happy to finally publish these results – it’s been a bit of a yak shave. But, a fun one! 😁