This is just a quick remark that I’m on a podcast again! It’s programmier.bar and I’m talking with the hosts about Ruby & Rails!
You can listen to the episode on various platforms. It’s meant to be a good listen for beginners and tech interested people as well. It’s in German though, so sorry to the English speakers.
No, I’ve not gone to the click-baiters (“10 tips that will change your life today!!!”), but I chose to limit myself to just 10 so that I don’t pull what is considered a “Tobi” and spend days writing a blog post so huge no one wants to read it anyhow. I’ll write a follow-up post with more 🙂
Anyhow, what are “gotchas”? For this purpose I’d define them as “slightly confusing or irritating behavior, prone to lead to errors especially when you’re new to Elixir“. There are good reasons for many of these, however some of them are also more arcane. Running on the great basis that Erlang built is probably Elixir’s biggest asset – it gives us a lot of functionality and properties that helps Elixir thrive especially in the modern multi-core and multi-node environment. However, Erlang also comes with its fair share of baggage as a programming language conceived almost 40 years ago. Erlang’s focus on backwards compatibility also means many of these decisions still live on today.
The list is brought to you by:
My own experience learning Elixir
Me teaching Elixir to folks both at Liefery and at Remote over the years
Horrifying discoveries in production code
Apologies for the lack of syntax highlighting, but wordpress borked the last way that was working for elixir and I didn’t want to yak shave this too far. I hope that you can sill enjoy them and may learn from them!
1. A list of numbers becomes text in iex
Let’s start with an oldie but goldie that pretty much every beginner book tells you about: Why does this random list of integers print out as text?
iex> [69, 108, 105, 120, 105, 114]
~c"Elixir"
This is because charlists, denoted by ~c"text" or 'text', are actually just that – a list of integers. So iex literally can’t tell the difference and does its own best guess work: it checks if the integers are in a range between 0 and 127 and will then print it as text.
You can also show that it literally is a list by using Enum functions on it:
The first line changes the integers to be outside of the printable range with +100 so iex prints it as a list of integers again. The second one just uses the knowledge that the difference between lower case and upper case letters in ASCII is 32 to transform it.
2. Charlists vs. Strings
All this brings us to the following questions: Why do we even have charlists and strings in elixir? What’s the difference between them? When do I use which one? Great question! It’s a source of a lot of confusion, esp. since in most languages single and double-quoted strings only sport minor differences – in Elixir they are backed by entirely different data structures. While single-quoted strings are just a list of integers, double-quoted strings are UTF-8 encoded binaries and so resemble strings you are used to in most modern programming languages.
As a rule of thumb, use strings aka double-quotes ("string"). The major use case for charlists / 'charlists'/~c"charlists" is interfacing with erlang or erlang libraries. Or in the words of the documentation:
In practice, you will not come across them often, only in specific scenarios such as interfacing with older Erlang libraries that do not accept binaries as arguments.
The other mystery here are the 2 different syntaxes in use for charlists – single quotes ('charlist') vs. the ~c"charlist" sigil. That’s a rather recent development, it was changed in Elixir 1.15, after some discussion. The reason for this is what I mentioned initially – it caused a lot of confusion:
In many languages, 'foobar' is equivalent to "foobar", that’s not the case in Elixir and we believe it leads to confusion.
So, it’s now less confusing but still confusing – which is why it made this list.
3. %{} matches any Map
Pattern matching is one of Elixir’s chief features! You can see it utilized frequently, for instance in a recursive function where we want to end recursion on empty list:
def list([]) do
IO.puts("list is empty")
end
That works flawlessly, however if you try the same with a map it’ll always match – no matter the map:
def map(%{}) do
IO.puts("Empty map or is it?")
end
iex> map(%{not: "empty"})
Empty map or is it?
The reason is simple – pattern matches on lists and maps just work different. In a list we’re looking for an exact match of the elements, whereas for maps it is basically checked if the structure is included:
iex> [a, b, c] = [1, 2, 3]
[1, 2, 3]
iex> [a, b, c] = [1, 2, 3, 4]
** (MatchError) no match of right hand side value: [1, 2, 3, 4]
iex> [] = [1, 2, 3]
** (MatchError) no match of right hand side value: [1, 2, 3]
iex> %{action: action} = %{action: "learn"}
%{action: "learn"}
iex> %{action: action} = %{action: "learn", more: "can be", provided: true}
%{
more: "can be",
action: "learn",
provided: true
}
iex> %{} = %{action: "learn", more: "can be", provided: true}
%{
more: "can be",
action: "learn",
provided: true
}
iex> %{action: action} = %{no_action: "sad"}
** (MatchError) no match of right hand side value: %{no_action: "sad"}
If you do want to execute a function only when given an empty map you can use either of the following guards: map_size(map) == 0 or map == %{} – which also showcases the difference between the match (=) and equality (==) operators. One full example from the docs:
def empty_map?(map) when map_size(map) == 0, do: true
def empty_map?(map) when is_map(map), do: false
4. Structs are Maps
While we’re in the topic of maps let’s talk about structs! We can easily create and use a struct:
iex> defmodule Human do
...> defstruct [:name, :age]
...> end
iex> tobi = %Human{name: "Tobi", age: 34}
%Human{name: "Tobi", age: 34}
It gets more interesting around pattern matching again, let’s try %{} from the previous section:
It matches and it is a map! Structs are nothing more than special maps with a __struct__ key that tells it which struct it is. It gets even weirder when you know that some of the built-in data types are structs and hence maps:
We can see their map nature more easily in an example! With a bit of meddling we can also tell IO.inspect to not print a prettified version showing us the real map underneath:
Now, you might think this all doesn’t matter too much. But it does! Be aware that every pattern match on a map might also match on a struct with the same keys, so will every is_map check. And yes, dates and ranges may match as well as shown above:
iex> %{first: number} = 1..10
1..10
iex> number
1
I have seen bugs in code that first matched on something being a map and only later matched on specific structs. So, instead of the struct specific code the more general map code was run – and hence another hard to track down bug was born.
So, I just told you that structs are just maps. But then you try to use random key access via [] on them and you are confused again:
iex(18)> tobi[:age]
** (UndefinedFunctionError) function Human.fetch/2 is undefined (Human does not implement the Access behaviour
You can use the "struct.field" syntax to access struct fields. You can also use Access.key!/1 to access struct fields dynamically inside get_in/put_in/update_in)
Human.fetch(%Human{name: "Tobi", age: 34}, :age)
(elixir 1.16.0-rc.1) lib/access.ex:309: Access.get/3
iex:18: (file)
iex(18)> tobi.age
34
iex(19)> map_tobi = %{name: "Tobi", age: 34}
%{name: "Tobi", age: 34}
iex(20)> map_tobi[:age]
34
iex(21)> map_tobi.age
34
As usual, elixir is amazing and already tells us that the problem is that the struct doesn’t implement the Access behaviour. As structs have predefined keys, you should use the dot-syntax of struct.key to access them. However, since sometimes you do still want to randomly access struct keys you can use the fact that structs are still just maps to your advantage using functions like Map.get/3:
You can also take it further than that and use get_in/2. It doesn’t work in a plain attempt, but can work thanks to Access.key/2:
iex(25)> get_in(tobi, [attribute])
** (UndefinedFunctionError) function Human.fetch/2 is undefined (Human does not implement the Access behaviour
# etc....
iex(25)> get_in(tobi, [Access.key(attribute)])
34
Be mindful to only use these if you really do need random key access on structs. Otherwise there are many other ways, such as good old plain dot-based access or pattern matching even.
6. Keyword lists are a bit awkward as options and in pattern matches
Another somewhat special data structure in elixir are keyword lists. Again, these are backed by “syntactic sugar” on top of lists. A keyword list is a list of 2 element tuples, where the first element is an atom.
iex> [{:option, true}] == [option: true]
true
When you call functions with keywordlists as the last argument you can even omit the brackets as seen before when we wrote IO.inspect(tobi, structs: false) – structs: false is a keyword list here. These properties make it the default data structure for passing along options to functions in Elixir.
However, since it’s a list the order matters here (and keys can be duplicated!) which often isn’t what you want for options: order usually doesn’t matter and duplicated options should not be a thing. It’s great for DSLs such as ecto, but when used as options it means it’s hard to pattern match on them. Let’s check out the following function:
def option(warning: true) do
IO.puts "warning!"
end
def option(_anything) do
IO.puts "No warning!"
end
It only matches when our options are exactlywarning: true – any additional data makes it a different list and hence fails the pattern match:
It’s an issue I struggled with early in my Elixir days. There are plenty of solutions for this. What I do in benchee is accept the options as a keyword list but internally convert it to a map (well, actually a struct even!). So, internally I can work with a nice structure that is easy to pattern match, but preserves the nice & idiomatic interface.
You can also use Keyword.get/3 to get the value of whatever option you’re looking for. You can also use Keyword.validate/2 to make sure only well known options are supplied and that you provide good defaults – hat tip to Vinicius.
7. Everything can be compared to Everything
Another surprise might be that you can compare literally every elixir term with one another without raising an exception:
Most people would probably expect this to raise an error as it does in many other languages. It doesn’t, as Elixir does structural comparisons and follows Erlang’s term ordering which basically gives all terms a predetermined order:
number < atom < reference < function < port < pid < tuple < map < list < bitstring
Why is it done like this?
This means comparisons in Elixir are structural, as it has the goal of comparing data types as efficiently as possible to create flexible and performant data structures.
All in all being able to compare everything to everything may sound mildly annoying but can also lead to some really bad bugs. In a conditional, this will just silently run the wrong code:
iex> maximum = "100" # forgot to parse
"100"
iex> if 9999 < maximum, do: "you pass"
"you pass"
I have seen similar bugs in production code bases, esp. since nil also doesn’t raise and is more likely to slip through. Thankfully, if you try to compare structs elixir issues a warning these days:
iex> %Human{} > nil
warning: invalid comparison with struct literal %Human{}. Comparison operators (>, <, >=, <=, min, and max) perform structural and not semantic comparison. Comparing with a struct literal is unlikely to give a meaningful result. Struct modules typically define a compare/2 function that can be used for semantic comparison
└─ iex:6
true
iex(18)> ~D[2024-05-01] > ~D[2024-05-02]
warning: invalid comparison with struct literal ~D[2024-05-01]. Comparison operators (>, <, >=, <=, min, and max) perform structural and not semantic comparison. Comparing with a struct literal is unlikely to give a meaningful result. Struct modules typically define a compare/2 function that can be used for semantic comparison
└─ iex:18
false
Whoops, there is that warning again! Obviously, we shouldn’t compare them like this – but it still works, and might even produce the correct result by accident slipping through tests!
In that last example map[:d] returns nil and then nil[:b] evaluates to nil again without crashing. If you wanted to assure that the keys are there, you got a lot of possibilities but one of them is pattern matching:
iex> %{a: %{b: value}} = map
%{a: %{b: :c}}
iex> value
:c
iex> %{d: %{b: value}} = map
** (MatchError) no match of right hand side value: %{a: %{b: :c}}
10. How to use constants
Another question that’s common among Elixir newcomers is: “Cool, so how do I define constants?” and the answer is… there are no real constants in Elixir/Erlang. The best workaround we have are module attributes. However, they are not visible to the outside by default so you have to provide a function to access them:
defmodule Constants do
@my_constant "super constant"
def my_constant do
@my_constant
end
end
iex> Constants.my_constant()
"super constant"
That works, however one unfortunate thing about module attributes is that they aren’t… you know, truly constant. You can redefine a module attribute later on in a module without any warning and if you then use it again below the new definition – with its value will have changed:
defmodule Constants do
@my_constant "super constant"
def my_constant do
@my_constant
end
@my_constant "ch-ch-changes!"
def my_constant_again do
@my_constant
end
end
Interestingly, the value is not changed retroactively so my_constant/0 still returns the original value (and is a true constant in that sense). But it can change throughout the module, which is necessary for other use cases of module attributes. So, if you accesses it in a function and someone happened to define it again with a newer value above, you may be in for a bad time.
Hence, I whole-heartedly agree with my friend Michał here:
We need proper first-class constants in Erlang that a module can define
It’s also worth nothing that you don’t need module attributes – you can also just define a function that returns a constant value:
def my_other_constant do
"This is cool as well"
end
In many cases, the compiler is smart enough to realize it’s a constant value (even with some operations applied) and so you won’t suffer a performance penalty for this. However, there are cases where it doesn’t work (f.ex. reading a file) and certain guards require module attributes (f.ex. around enum checking). Hat tip to discussing this with José.
Hope you enjoyed these gotchas and they helped you! What gotchas are missing? Let me know in the comments or elsewhere and I’ll try to cover them in future editions – I still got ~10 on my TODO list so far though 😅
It’s also worth mentioning that Elixir is well aware of a lot of these – if you follow the links I posted, they will frequently send you to Elixir’s own documentation explaining these. From the early days, there have also already been quite some improvements and more warnings emitted to help you. As Elixir is amazing, and cares a lot about the developer experience.
If you enjoyed this post and think “Working with Tobi may be cool!” – you’re in luck as I’m still looking for a job – so give me a shout, will ya? 💚
It’s that time: I’m looking for a job! I know y’all ain’t got much time, so I’ll first do a short version and then one with more detail.
If you want to help me, please help spread the word 💚 If you have the time and know me, leave me a recommendation – both by spreading and if you have the time on LinkedIn – seemingly I never needed one before and some folks are like “yo, what’s up with that?” 😅
The short version
I’m an experienced leader & product-minded engineer deeply interested in collaboratively building useful products. With a background spanning small startups to scaling unicorns, I bring a wealth of experience in Elixir, Ruby, SQL and some JavaScript. I love Open Source, participating in the community and giving talks. My passion for performance optimization and benchmarking led me to create benchee.
In my most recent role as a Senior Staff Engineer @ Remote, I led teams to success by removing obstacles, fostering a culture of collaboration and filling the gaps. Whether managing a product department of 15 or mentoring junior developers, my greatest joy comes from empowering others. I am fascinated by the human side of software development and continually strive for the optimal balance between immediate value delivery and long-term sustainability.
I’m now seeking new opportunities where I can leverage my skills and experience to make a meaningful impact. While I excel in roles like Staff+ Engineer, I’d love to explore opportunities in smaller companies or leadership positions such as CTO, Head of Engineering or Team Lead. Remote and asynchronous work environments are ideal for me, as they allow me to focus on delivering value while maintaining a healthy work-life balance.
I’m considering both full time positions as well as freelancing opportunities either in Berlin or remotely.
If you want to get in touch, just drop me an email at pragtob@gmail.com.
Let’s get into some more detail, if you’re here to stay:
Who am I and why would you want to hire me?
My name is Tobi, on the web I’m known as PragTob. I won’t repeat too much of the “short version” above here – read it if you haven’t yet!
So, what kind of work have I done? I was a Senior Staff Engineer @ Remote helping the company scale according to its unicorn status, which included scaling up both the team (hiring and structure), the processes and the application architecture. I was responsible for the FinTech domain there – moving many millions each month securely, correctly and quickly. I enjoy the ambiguous nature of Staff Engineering work as well as the possibility to contribute in a variety of ways to have the biggest impact.
I’ve also worked as a people manager – functioning as a de facto head of engineering managing the entire product department of ~15 people. It’s a work I also deeply enjoy. It’s hard to say what I enjoy most, I think I enjoy being in a position where I can help improve things.
What can I help you with?
Shipping features with a holistic view of the product in mind
Collaborate on all the things™
Taming big legacy applications
Build the first version of a product and then hire the team to continue leading it
Scale up your existing team
Identify areas of technical improvement, weigh them and if worthwhile execute on them
Level up the team
Improve and streamline processes
Identify and fix performance bottlenecks
Just in general my experience, I’ve seen agencies, small startups, supported a unicorn growing from ~150 to ~1000 employees in a year and I worked at a tech giant – you see and learn a lot of things
The main technologies I’ve used and worked with:
Elixir, Ruby & JavaScript (a bit rusty on JS, but I recently passed a React interview 😁)
MVC frameworks (Rails, Phoenix)
SQL databases (PostgreSQL)
Monoliths and taming them (such as Domain Driven Design)
I also have experience around microservices, extracting applications etc.
Building APIs
Background Job Systems (Sidekiq, Oban)
Performance Improvements and in particular I love benchmarking
Test Driven Development (ExUnit, RSpec…) and acceptance tests
Both Functional Programming and Object Oriented Programming
Beyond that I believe that some of the most important skills are people and organizational skills:
Navigating big organizations to find valuable tasks or information
Understanding the product & stakeholders at a deep level
Hiring (selection, interviews, designing tasks)
Mentoring & skilling up
Running effective meetings
Getting people on the same page to make sure we ship what is needed
Continuously learning
Beyond that I’ve been running the Ruby User Group Berlin for the past 11+ years. I speak at conferences and meetups (and even used to run conferences) about a wide variety of topics: from Communication & Collaboration over Benchmarking best practices all the way to Application Architecture. My most recent talk details my journey through Open Source.
Speaking of which, the 3 major open source projects I contributed to in major ways are:
benchee – I’m a benchmarking nerd, this is the default (& very powerful) benchmarking library in elixir which I created
simplecov – I became one of the maintainers of simplecov, the default code coverage library in Ruby
Shoes4 – a Ruby GUI toolkit & DSL I spent many years pushing forward building on the works of legendary programmer “why the lucky stiff”
What am I looking for?
With my many interests this is difficult to say. Mainly, I’m looking for a company that is building something meaningful where I can help them achieve their goals. My absolute dream job would be someone just paying me to work on improving the Open Source Ecosystem in Elixir or Ruby – but I know that ain’t happening any time soon 😅
Much like a job ad, it’s unlikely for a job to tick all of the boxes and that’s fine – especially in the current tech climate. I’ll still break my preferences down more:
Position: There are too many positions I can envision myself doing depending on the circumstances. I want to be somewhere where my impact can go beyond code as I love to help people and improve processes. What that means is up to the situation: One day it’s shipping a feature, then it’s fixing a bug, the other day it’s mentoring someone, the next it’s hiring, then it’s talking to a customer to understand what they need – I’m flexible. A rough overlook of what I can imagine:
Staff+ Engineer – this has been my 2 most recent roles, it’s ambiguous, it’s hard and I love it. The technical leadership, the flexibility, the potential impact on an organization – it can be so rewarding. I love it so much, I gave a talk about what it is. Sadly, the position isn’t common everywhere and especially not in smaller companies.
Founding Engineer/Early CTO/Head of Engineering – I believe my combination of technical skills, product understanding as well as ability to grow and manage teams positions me perfectly for this. I can build the product and be hands-on while ramping up the team. It’s a role I wanted to work in for a long time.
Manager/Team Lead/Head of Engineering/CTO – the difference to the above being a more mature company here. I’ve run a department of 15 and have since also gathered a lot more leadership experience, albeit as a Staff Engineer in huge companies but the technical leadership required there isn’t too different. I can help teams & products flourish.
Senior Software Engineer – in the right circumstances I could be “just” a Software Engineer again.
Developer Relations – through my open source and speaking I could also do well in DevRel or a related field. That said, I don’t think near constant travel suits me.
Location: Hybrid in Berlin or remote. I’m not looking to relocate and I don’t want to go back to the office full time at this point in time.
Business Domain: I love helping people solve real problems. I’d love to work on supporting people with mental illnesses for instance, as I see a lot of potential there. There are many good things out there, it’s easier to say what I don’t want to work with. I absolutely do not want to work on crypto currencies. Similarly, privacy-invading, gambling or products for the super rich aren’t something that interests me in particular. Working for a consultancy or agency also isn’t high up on my list, as I prefer to stay with a product for a longer time and don’t like constant travel (as in, living in a hotel for months).
Employment Type: I’m open to both full time employment and freelance work. If you see this and think you might need my help with something but it’s not a full time position – get in touch!
Tech Stack: I’m flexible on the tech stack – I believe in the right tool for the job and I’m happy to learn new things. That said, my core competencies are in Elixir (💜), Ruby & SQL.
Work/Life Balance: I’m not someone who’ll work nights and weekends on the regular. When something is burning, sure I will – but not as a regular mode of working. I believe in going at a sustainable pace if you want to go far.
Company Culture: I love companies that trust their employees, to allow for flexible working hours and locations. Supporting people in their growth is also something I value, for instance that going to and speaking at conferences is supported. Similarly, I appreciate companies who take the time to give back to the open source community.
I hope this gives you a good overview.
Getting in touch
Piqued your interest? You can check out my CV again. Feel free to send me an email to get in touch with me at pragtob@gmail.com!
Also, if you spread this in your network, I’d really appreciate it!
Look, a random picture of me so that it looks nicer and things pick it up when sharing apparently!
Welcome to the last part of the interview series! In this part we’ll take a look at more general interviews – usually they cover a variety of topics. They also heavily depend on the company. For this purpose the following sections will be split into a bunch of broader topics of discussions (Employment History, Technical Experience etc.). Depending on the interview type you may talk about all of these, some of these or only one of these in specialized interviews. The main focus here are interviews of Senior+ engineers – that said, the concepts are the same but of course the requirements differ for more junior engineers as well as people managers (although we’ll touch on the latter).
Each section will introduce the general topic with some tips and why questions in this bucket may be asked. Each section will feature a list of example questions that may be asked in an interview. It’s important to note that these aren’t necessarily questions I recommend asking as an interviewer. I purposefully include questions I wouldn’t ask, because the goal of this post is to prepare people for interviews they might really encounter in the wild. And the reality is, not all interviews are great.
Why should you read on and think about these? Sadly, interviews are very stressful situations for the candidate. A great interviewer will try their best to make you feel as comfortable as possible, but they can never alleviate all the pressure. Moreover, some don’t care. Regardless of the circumstances it can be tough to answer questions “on the spot”. This is especially tough for some questions that require reflection and recalling specific situations – such as “Tell me about a mistake you made and how you fixed it.”. We all make mistakes. That’s clear. However, failing to come up with an answer on the spot can look extremely bad. Hence, I encourage you to think about the answers to some of these common questions in advance to be prepared and be able to answer and discuss them. I hope to help you succeed in an interview because you took the chance to reflect about some of these questions beforehand.
To set yourself up for success, ask before the interview what topics will be covered in the interview to be able to prepare yourself.
Now, what qualifies me to dish out tips & tricks on interviewing? Most recently I did 100+ interviews at Remote for Junior Devs all the way up to Staff Engineers and Engineering Managers. I also used to own the entire engineering hiring process at a smaller startup. Of course I’ve also done my fair share of interviewing as a candidate. With all that & more, I think I have some helpful tips to share. Also thanks to my friend Roman Kushnir for reviewing this and adding some key aspects.
Speaking of which, this the final part of an interviewing tips series, you can find the other posts here:
A good interview can feel like a good conversation – it flows naturally, and you talk about topics you’re interested in with nice people. That said, not all interviews are great. Some are outright terrible and fail you for no good reason at all. This is frustrating beyond belief. I highlight this so that you know: Failing an interview doesn’t have to be your fault. There’s a variety of reasons that can contribute to this, most prominent of all: biases. This can mean anything from the interviewer having preconceived notions of what makes a good employee which you’re not fitting or assumptions they make about you based on irrelevant factors. Sometimes interviewers are also just trained badly and forced to do interviews. Interviewing is by no means an objective, definitive process that always ends with the “correct” result.
At the end of the day always remember that interviewing is a two-sided process: You’re applying at the company but it’s also your choice whether you join the company or not. Naturally, this is a privileged perspective and if money is tight or the market is dry you won’t have as much choice. If you have the luxury to decide, the way the interview process works can be indicative of how a company works. Take note of the questions they ask – would you want to work with people selected by this process? I have aborted interview processes in the past because my answer to that question was “no”. I have in turn also felt right at home during an interview process, as I saw how I was valued and how they asked great questions. This made it much easier to accept their offer when it came to that. That said, sometimes the recruitment experience has almost nothing in common with the experience of working at a company – so take it with a grain of a salt as well.
Broadly speaking I think there are 2 approaches to interviewing: Seeing the potential and the positives in a candidate or looking for faults in the candidate. One of my favorite hires ever was Ali who had been rejected by 2 other companies before interviewing with us. This was mostly due to a lack of experience in current JS frameworks as her last job had an outdated tech stack. However, what we saw was a person who had extremely solid fundamentals in JavaScript, was honest, curious, wanted to learn and had an eye for improving processes and was able to reason extremely well. We hired her in a heartbeat, accounting for some ramp up time. She did so well that I wanted to promote her to team lead later.
Keep Calm
Interviewing can be extremely challenging but don’t stress it. Do your best. Stay calm.Take time to think. No one expects you to have all the answers ready at a moment’s notice. It is better to think for a bit than to blurb out the first thing that comes to mind. Ask clarifying questions when you don’t know exactly what is meant by the question. This can also give you some extra time to think about an answer. Make sure to also manage the time a bit: Talking without end can be bad as you might go off on a tangent they aren’t interested in. Always just giving the shortest answer also isn’t great though as the answer may lack nuance and detail. The ideal length of an answer varies wildly. I usually try to answer in a couple of sentences first and then check in with the interviewers: “Should I tell you more about this problem or would you like to know about something else?”. As I’m also bound to tell long stories I will often also say “Stop me if I’m going too far with this”.
Before the Interview
Don’t forget your research we talked about in the first blog post. Many companies use their company values to evaluate interviews: Make sure you’re aware of them, and highlight how you may relate to them in your answers. Knowing the domain of the company and the challenges they are facing right now might help you anticipate questions. If they have blog posts on their transition from a monolith to microservices, that topic is likely to come up!
Remember what the interviewers may be looking for. Generally that means taking the context into account. Especially on the higher career ladder levels there’s rarely a definitive answer – the answers are often some approximation of “it depends”. When someone asks you for your opinion on “Microservices vs. Monoliths”, even if you are firmly in one camp, it behooves you well to highlight that you know the limitations of both approaches. Show them that you can identify when your favorite approach might not be a good choice. Essentially, people often don’t look for someone who only knows their hammer but someone who may have some preferred tools while knowing when the other tools may be more useful – even if they aren’t experts in those tools.
For the last couple of minutes before the interview I’d suggest you to take some time to go over important information again to get ready and into the mindset for the interview. Checking the company values again is a great start, you can read the job description or company business model. I also open up my CV again so that I can refer to it when the interviewers ask about it. If I submitted any type of exercise before the interview, I’ll also briefly review it again.
Types of Questions/Topics
Before we go to the different areas: Of course these areas aren’t always clearly separated. There are gray areas and questions that may belong in multiple categories. It’s also common for one area to flow into the other. For instance an interview may start with “Why are you applying here?” to which your answer may include “Elixir” which will cause the interviewer to drill down on why you’re interested in Elixir.
This separation into sub-areas isn’t only made for convenience. For a “general non specific topic” interview these areas may broadly cover what interviewers want to talk to you about. Depending on the interview process, some of these might also have dedicated full interviews.
Introduce yourself
A classic of interviews – which I underestimated for the longest time. Until my friend Pedro Homero pointed out to me, in the first article of this series, that it’s essentially an elevator pitch for yourself answering the question “Why should we hire you?”. It also gives you the opportunity to guide the conversation – if you mention something that piques the interviewers’ interest, chances are they’ll ask you about it. So, use it to shine the lights on your strengths.
Recently I had an interviewing experience that was a bit too free-form. “Tell me about yourself” was essentially the only question I was answering – for an entire hour. I struggled a bit and only realized late into the interview that I forgot to mention some important facts, like my open source work or my presentations at conferences. This led to me creating a mind map of my biggest “selling points” that I then broke down into a couple of bullet points suitable for a ~2 minute introduction. These cover the breadth of my experience as well as some of the “special” things I did. You don’t need to go that far, but I’ve gotta say – it was a worthwhile experience for me.
Example Questions
Tell us about yourself
Employment History
One of the easiest ways to get to know you in a professional context is based on your employment history: What have you done so far and how has it led you to apply at this company? While it often focuses on your most recent jobs, it is a look at the decisions you’ve made so far in your career. What did you like? What didn’t you like? And most importantly: How has your experience so far made you a good fit for the position you’re interviewing for right now?
Naturally, the most dreaded questions here revolve around why you left a workplace. Be it the last one or why you only stayed at one place for a couple of months. A positive minded interviewer asks these questions to make sure that the position won’t have the elements that made you leave a job. The answer to these is delicate – no matter how unhappy you’ve been you shouldn’t completely trash your last company or boss. It’s not a good look on you. Many people opt for non-committal answers (“Time to move on”, “new challenge” etc.) and that’s probably the safest answer. That said, I’m often too honest for my own good and as such also appreciate honesty from candidates a lot. Knowing that you left because of micro management or due to too many meetings and overwork may be valuable for your interviewer and may help you avoid sliding right into the next bad situation. That said, it’s a fine line to walk. In one of the worst interviews I’ve ever been a part of, the candidate told us he left his last position because he “just wasn’t appreciated” and didn’t get the promotion he wanted. That can happen, but if it’s the same in the past three positions a pattern emerges and it’s not one of someone I’m likely to want to work with.
Another thing people may worry about are breaks in their CV. Usually these are completely fine, I have a few of them – when I can afford it I like to take a couple of months off to relax, do something fun but also spend some time on technology and then make a concentrated effort to find my next gig. I’m on one such break right now, which gives me the time to write this. Most people can empathize with this. Much like anything, it’s ok as long as you can share a good reason. For instance, you might think that only staying at a company for a month looks bad. However, if the company went bankrupt or you figured that the company had barely any direction or interesting work for you then those are fine reasons.
Overall people will want to look at what experiences you’ve made and how those experiences may help you be an effective part of their company. This is also your reminder that everything on your CV is fair game to ask about. And by that I mean that if someone says “It says on your CV you worked on X, tell me more about that” you should be able to talk about that subject for at least a couple of minutes if need be. If you can’t, consider dropping it from the CV. I’ve been in too many interviews where a candidate seemingly couldn’t recall anything about a point on their CV that intrigued me.
Keep in mind that while asking about past experiences interviewers are often interested in your reflections on the topic. They usually aren’t just interested in how processes worked at your last employer, but what you think about them and how they might have been improved.
Example Questions
Why are we here?
What are you looking for in joining our company?
Why did you quit your last job?
I see there’s a gap of 2 years in your CV here, what did you do during that time?
At company X you lead project Y – what was that like?
What was the development process like in your last company?
Who was the product for? Who were the stakeholders? How did it solve their problem? Why was it better than its competition?
How did the business model work?
Describe the development process of your last job. What could have been improved?
Tell me about a recent complex project you worked on
What was your role? What part did you work on?
Why was the project built?
What challenges did you run into?
Did the project accomplish its goals?
Who were the other team members? How did you work with them?
Technical Experience
This section is similar to the previous one in that it’s about your past experiences – here the focus is just more technical as well as probing your overall knowledge. These sections will usually flow in and out of each other. You’ll talk about your general experiences at an employer and at some point someone may decide to dig deeper into one of these. The questions can also appear separate from that, usually introduced by more specific questions like “Tell me about a complex project you worked on” or “You like technology X, when would you not use it?”.
One of the major goals here is to test your decision making and reasoning skills as well as your ability to explain. These questions are usually broad and leave you room to steer the conversation and showcase your knowledge. As a general rule of thumb, especially here your answers should be nuanced. The more senior you get, the more the answers usually entail some variant of “it depends”.
It’s easy to say too much or too little here. If you immediately dig really deep into a topic there is a chance you’re going off on a tangent the interviewers aren’t interested in at all, but find it hard to stop you (esp. In a video call interview). If you just say a couple of high level things without explaining any of it, it can give the impression that you don’t really know what you’re talking about. As an interviewer I always dig deeper: “I like elixir because of functional programming” Ok, but what does functional programming mean? And how does it help you, what benefits do you get from it? Sadly, there are many candidates who fail to explain concepts beyond the buzzwords. Aim to be able to be better and explain what these buzzwords mean.
I recommend an approach where you mention some high level points first but offer to dig deeper. So, if someone asked “Why do you like to work in elixir?” an answer could go something like this: “I think the functional programming approach, especially immutable data structures, makes code more readable as it’s easy to see what data changed. The code becomes a story explicitly transforming data. I also like how parallelism is baked into everything leading to faster compile and test run times. That coupled with the resiliency of the BEAM VM makes for a great platform. I trust the creators of the language and the ecosystem – they often surprise me positively with the problems they decide to tackle. For instance, I really like how explicit ecto is in its database interactions and how much direct control it gives to me. Do you want me to dig deeper into any of these?”. Of course your answer can’t be that prepared – I wanted to emphasize here how important it is to highlight things that you like, but also why you like them to open up a potential discussion.
To close this off, some of the most heartbreaking but also definitive “No”s I have given as an interviewer were for senior engineers who changed the entire tech stack of their previous company – and when asked about it couldn’t give me a better reason other than that they “liked it better”. That’s a fine reason to rewrite your hobby project, not to change a company’s tech stack though no matter if I agree with your choice or not. My expectations for Senior+ engineers are much higher than that.
Example Questions
Why do you like to work in technology X?
Is Technology X always the best choice? When would another technology be better suited?
You remodeled the entire architecture at company X – why did you do that? Would you do it again? What motivated the change? How was it planned?
What’s a mistake you made? How did you fix it?
Tell me about a big refactoring you did. Why was it necessary? Was it a success? How can you tell?
What’s a technical design you’re proud of?
What was the last down time you were involved in? What happened? What steps were taken to prevent it in the future?
What makes code good vs bad?
What do you look out for when reviewing a PR?
Microservices vs. Monoliths – what’s your take?
What’s your approach to testing?
How do you deal with technical debt?
How do you deal with growing/large code bases? What pains do appear? How can you mitigate those?
How do you go about changing coding guidelines and patterns in a big application with a big team?
Talk to me about using inheritance vs. composition.
When should you use metaprogramming?
Technical Knowledge
I might need to work on naming here, but what this section means is that there are parts where interviewers “quiz” your knowledge base. As opposed to the previous section, there are usually right & wrong answers here and much less “it depends”. They’re looking to gauge how “deep” your knowledge is in a certain area with very specific questions. Sadly, sometimes this one can feel like an interrogation – keep calm, and also be aware that it’s usually ok to not have all the answers. Whatever you do, don’t try to confidently act like you know the answer but say something that’s a guess at best. This may be my bias, but I’d much rather work with someone who admits they don’t know but then give me a guess (that may or may not be correct) rather than someone who confidently tells me something they know is probably wrong.
These questions are usually very job and technology dependent. You can google “Technology X interview questions” and you’ll find a lot of suitable ones. I won’t enumerate all of them here, just a couple to illustrate common questions I have seen. A poster child example may be “What are indexes in SQL? When should you use them?”. Naturally these can also show up during another part of the interview. For instance, if a candidate forgot some indexes during a coding challenge I’ll usually ask them about it.
Sadly this section comes with one of my favorite interviewing anti-patterns: Interviewers asking people about things that they just learned. I’ve seen and heard about this many times. Basically there was just a big problem, they noticed something has always been done wrong at the company and no one had caught it. Now they interview everyone for that knowledge they just acquired. The irony to me is, that no one at the company would have passed that interview as they all were doing it wrong forever. So, unless you think everyone at your company, including yourself, should be fired please don’t do this.
Example Questions
What’s a join in SQL?
What are database indexes? Why don’t you just index all fields?
How can you manage state in React?
What makes your web page accessible?
What is CORS?
What is XSS?
What does MVC stand for? How does it help & why is it necessary?
If Assembly is so efficient why don’t we write all programs in it?
What is DNS? How does it work?
What happens when you initiate an HTTP request?
What is multithreading?
What is a GenServer? How do you use it? What do you need to watch out for?
In ActiveRecord there are often 2 variants of the same function, one with ! and one without. What’s the difference? When do you use which one? Why?
What’s an n+1 query and how do you avoid it?
What are your favorite new features of $new-prog-lang-version ?
Tell me about a function in the standard library of $prog-lang that you really like but maybe not everybody knows about?
What is DDD?
Leadership Experience
Leadership – at any level comes with its own kind of challenges. Generally speaking, the more senior the position you’re applying for is, the more you’ll have to answer questions of this nature. I’ve lumped technical leadership (Staff+ Engineering) and people leadership (Engineering Management) into one category here. While there are some questions you’ll usually only have to answer as a people manager I think they are close enough. Depending on the position, most of the interview may be spent in this section. Hiring new leaders & managers has always been one of the most daunting tasks to me. There’s so much upside when you get it right, but also so much downside when you get it wrong – as anyone who ever had a truly terrible manager can attest to.
Oftentimes these questions concern your ability to lead: Be it to ship projects, cause organizational change or help & grow those around you. These will usually be asked and discussed with concrete examples – so it’s best to have a couple of projects and situations at hand that you can talk through. You can find even more of those in the following “reflective questions” section.
Don’t let all the talk of manager roles here fool you though – these questions may also be asked for Senior or mid-level roles. Leadership at every level.
Example Questions
When leading a project, how do you make sure everyone is on the same page?
What does it mean for a project to be successful? What can you do to make it successful?
What’s the last failed project you’ve been a part of? What made it a failure? What would have been needed to make it a success?
Have you ever mentored someone? What about? How do you mentor?
What properties does a good hiring process have?
Tell me about a change you initiated for your team/organization.
On a daily basis, how do you interact with your reports? What are topics for 1o1s?
Did you have to give negative feedback? What happened? How did you try to help improve the situation?
How do you onboard someone new onto the team?
Tell me about a situation you were pulled into to help out and fix a situation.
How do you handle promotions?
Reflective Questions
Essentially interviews are a big exercise in reflection: About your employment journey, the decisions and experiences you’ve made along the way as well as the technical knowledge you acquired. Nowhere is this more apparent than when explicit reflective questions are asked. The poster children of this are “What are your strengths?” and “What are your weaknesses?”. I implore you to be as genuine as you can be while answering them. If you just repeat some of the default answers websites give out, good interviewers will sniff that out. Of course the one for weaknesses is commonly “Oh, I’m too perfectionistic.” – aka say a weakness, that actually isn’t one. To me, it’s a bothersome balance as being too perfectionistic is actually one of my weaknesses. It’s something I try to pull myself out of, to get more done without much loss of quality. Instead of painstakingly cataloging everything in detail, maybe a higher level overview that I can do in 20% of the time is actually better. Why do I tell you this? As with basically all of the advice here, there’s always a chance it doesn’t apply. So, if one of those “standard” answers is your actual honest answer, then go for it but also put in the work to make your interviewers believe it.
For many of these you may ask: “Why are people asking this? Do they actually expect me to tell them my weakness?” and the answer to that is: Interviewers want to see that you understand what your limitations are. That’s an important part of self-reflection. We all have weaknesses, pretending we’re perfect either means we’re delusional, lying or have 0 self-reflection – none of which bodes well for a future colleague. I wanna hammer this home, instead of pretending a negative thing doesn’t exist, acknowledge it and highlight how you’re dealing with it.
As a further example: “Tell me of a conflict you had at work”. First off, it can usually be rephrased to a “disagreement” – culturally, conflict seems to have wildly different connotations around the world. Saying “Oh, I never had any conflict/disagreement” is probably the worst answer. We all have conflicts. Be it about the direction of the company, a project or just code style – it happens. Tell a real story. This is why preparing for interviews can be beneficial – coming up with a story in the heat of the moment can be tough. I’ve created a mind map mapping many common reflective questions to a variety of experiences I’ve made. This helps me recall them during interviews.
Lastly, also filter the stories you tell somewhat. Preferably your story shouldn’t end with you leaving the company out of frustration. There’s only so much time in an interview, recounting a highly complex and nuanced situation may usually not be in your best interest: There are too many chances for the interviewers not to understand it completely or have doubts about how it unfurled. Hence, something simpler without being simplistic works – at best with a “happy end”. That said, one of my favorite stories to tell is how I left a company after a burlesque dancing incident and related concerns around sexism. It ends with me leaving the company after trying to improve the situation. I like to tell the story, as I hope that it sends a strong signal that I stand by my values and if there are similar problems present at the company I probably wouldn’t want to work there.
Example Questions
What are your strengths?
What are your weaknesses?
Tell me about a mistake you made. How will you avoid making the mistake in the future?
What was a big success for you?
What would your … say about you – positive & negative? (… being anything from colleagues, to manager, to CEO or even mother/father)
Tell me about a conflict you had at work?
What happened?
How did you resolve it?
Tell me about a time you changed your perspective on something important to you.
What could you have done better at your last job?
What processes would you like to improve at your last job?
Why are you a programmer and not a product manager? Why are you a Team Lead instead of a Staff engineer?
What is something you want to get better at?
Your Questions in the end
Many companies these days reserve time for your questions in the interview, highlighting that interviewing is a 2-way process. Generally speaking, these should not be part of the interview evaluation. They should be there for you to genuinely figure out if it’s a place that you want to work at. This is also in the interest of the company, after all hiring someone just for them to quit again just months later is a gigantic waste of resources for the company. That said, it isstill part of the interview. If the interviewers had already gotten the impression that you’re only interested in the technical side and not product or people, only asking about their tech stack and specific libraries they use will reinforce that image.
You don’t have to ask questions, however it can show a lack of interest in the company if you don’t ask a question. Hence, I’d recommend you to ask questions around topics that interest you. You have direct access right now, use it! What would impact your decision to work there? Ask about it! Usually this includes questions surrounding the way of work, culture and the tech stack.
Here are some topics you can ask about, given they haven’t been answered before or aren’t part of easily available public documentation:
What do they like about company X? What do they dislike?
Details about the tech stack
What does a day in the life of a $your-position look like?
What’s the biggest challenge facing the company right now?
How many meetings do you have in a given week?
$specific-question-about-company-business-model
What helps someone be successful at company x?
What do you wish you knew before you started working here?”
Now, if you face the opposite problem – you have too many questions, but not enough time to ask them – what should you do? Well, now you’re the interviewer, so moderate time well. Let them know you have a lot of questions and ask for short answers. Also, don’t be too afraid to interrupt them when they’re going off on a tangent. Ultimately, usually you have the possibility to ask your recruiter more questions or ask them during the next interview!
Bonus-Tip: Reflection
Well, thanks for making it so far – it’s been a long blog post. I’ve thought for a long time about what it may be that usually makes me perform well in interviews. And I think I identified something! It’s this right here. No, not you reading this blog post. Me, writing it. I do a fair amount of writing about work related topics, I give talks and I talk with a lot of people about work. What I really do is take time to reflect. Having discussed a topic or situation before – no matter if in a blog post or with friends over a beer – makes you better at talking about the same situation in an interview. To be clear, it’s not about publishing any of this and what may come with it. I’m talking about the process of reflection via writing & talking – even if it never got published. It may be worth writing down some of these key points, lest you forget them (again, I have a mind map for this).
To illustrate this point, the easiest interview I probably ever had was a “Tech Deep Dive”. I was supposed to come prepared to talk about a complex technical topic for an hour. I talked about the design and implementation of my benchmarking library benchee. I didn’t even prepare for it. I didn’t need to, at this point I had given multiple talks about benchee – I could talk about it and all its design tradeoffs in my sleep. The interview was a breeze. It’s an extreme example and I realize not everyone will be this lucky but I hope it helps illustrate the point.
Another great time to reflect is right after the interview! How do you think the interview went? Were your answers on point? Did you go off track or get to the point too slowly? Was there a question you struggled to answer? How could you improve your answer the next time around? All this helps you get better throughout the process of interviewing!
Closing
One of my other, but related, weaknesses is keeping it short as I always feel the urge to cover everything – can you tell? 😉 I hope this was helpful to you, despite or exactly because of it. Interviewing is tough. Running into a specific question that you know you should have an answer for but can’t come up with on the spot can feel devastating. Hence, I hope the catalog of example questions in this post will help you avoid this situation going forward. Of course, it’s also not fully comprehensive – I get surprised with questions in an interview every now and then still. Also, remember it’s not necessarily your fault. Sometimes interviews just suck and failing them is more on the interviewers or the process than it is on you. Stay calm and keep going.
And somewhat belatedly the slides I presented at the Ruby User Group Berlin February meetup almost 2 weeks ago 😅 I’ve been extremely busy, so sorry for the delay.
“Going Staff” seems to have been one of my most anticipated talks as it’s an interesting topic that is still only picking up. It’s also a topic I’ve been thinking a lot about and that I’m also extremely passionate bout. A 7 page “draft mixed with outline TODO” blog post (more like mini book) is still in my Google drive on the topic. Sadly, there is no recording of the talk and my slides usually lose ~95% of their value without me speaking alongside them. However, I thought I’d still share them. Maybe I’ll get it into a conference so I can share a recording at a later point!
If you want to learn more in the mean time, “The Staff Engineer’s Path” by Tanya Reilly is a very warm recommendation from my side for everyone in engineering – not just staff engineers or those who want to become Staff+ engineers. It does a wonderful job of showcasing the ambiguities and challenges I’ve dealt with on the job & in technical leadership of organizations as a whole.
What’s up with becoming a Staff Engineer? What does it mean? Is it just for people who want to keep coding? How do you become a Staff Engineer and what does the work entail? What if I told you, that being a Staff engineer actually required a lot of communication and collaboration skills?
In this talk, let’s answer all those questions – as it’s still quite fuzzy what a Staff engineer actually is.
Back last year in June 2023 I was lucky to speak at lambda days 2023 about one of my favorite topics: Open Source! And it’s not just Open Source, but it’s my story in Open Source and my journey throughout Open Source – so far. As such, it’s by far the most personal talk I’ve ever given. So, within the talk you won’t just learn about how to run Open Source projects, how to contribute to Open Source projects and how to get better at something – but you’ll also learn about where I went for ERASMUS, my connection to Ukraine and the health situation of bunnies. I swear it makes sense in context!
What’s it like to work on Open Source projects? They’re all the same aren’t they? No, they’re not – the longer I worked on Open Source the more I realize how different the experience is for each one of them. Walk with me through some stories that happened to me in Open Source and let’s see what we can take away.
body-recursive was fastest on input sizes of lists the size of 100k and 5M, but slower on the smallest input (10k list) and the biggest input (25M list). The difference either way was usually in the ~5% to 20% range.
tail-recursive functions consumed significantly more memory
we found that the order of the arguments for the tail-recusive function has a measurable impact on performance – namely doing the pattern match on the first argument of the recursive function was faster.
So, why should we revisit it again? Well, since then then JIT was introduced in OTP 24. And so, as our implementation changes, performance properties of functions may change over time. And, little spoiler, change they did.
To illustrate how performance changes across versions I wanted to show the performance across many different Elixir & OTP versions, I settled on the following ones:
Elixir 1.6 @ OTP 21.3 – the oldest version I could get running without too much hassle
Elixir 1.13 @ OTP 23.3 – the last OTP version before the JIT introduction
Elixir 1.13 @ OTP 24.3 – the first major OTP version with the JIT (decided to use the newest minor though), using the same Elixir version as above so that the difference is up to OTP
Elixir 1.16 @ OTP 26.2 – the most current Elixir & Erlang versions as of this writing
How do the performance characteristics change over time? Are we getting faster with time? Let’s find out! But first let’s discuss the benchmark.
The Benchmark
You can find the code in this repo. The implementations are still the same as last time. I dropped the “stdlib”/Enum.map part of the benchmark though as in the past it showed similar performance characteristics as the body-recursive implementation. It was also the only one not implemented “by hand”, more of a “gold-standard” to benchmark against. Hence it doesn’t hold too much value when discussing “which one of these simple hand-coded solutions is fastest?”.
It’s also worth nothing that this time the benchmarks are running on a new PC. Well, not new-new, it’s from 2020 but still a different one that the previous 2 benchmarks were run on.
System information
Operating System: Linux
CPU Information: AMD Ryzen 9 5900X 12-Core Processor
Number of Available Cores: 24
Available memory: 31.25 GB
As per usual, these benchmarks were run on an idle system with no other necessary applications running – not even a UI.
Without further ado the benchmarking script itself:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The script is fairly standard, except for long benchmarking times and a lot of inputs. The TAG environment variable has to do with the script that runs the benchmark across the different elixir & OTP versions. I might dig into that in a later blog post – but it’s just there to save them into different files and tag them with the respective version.
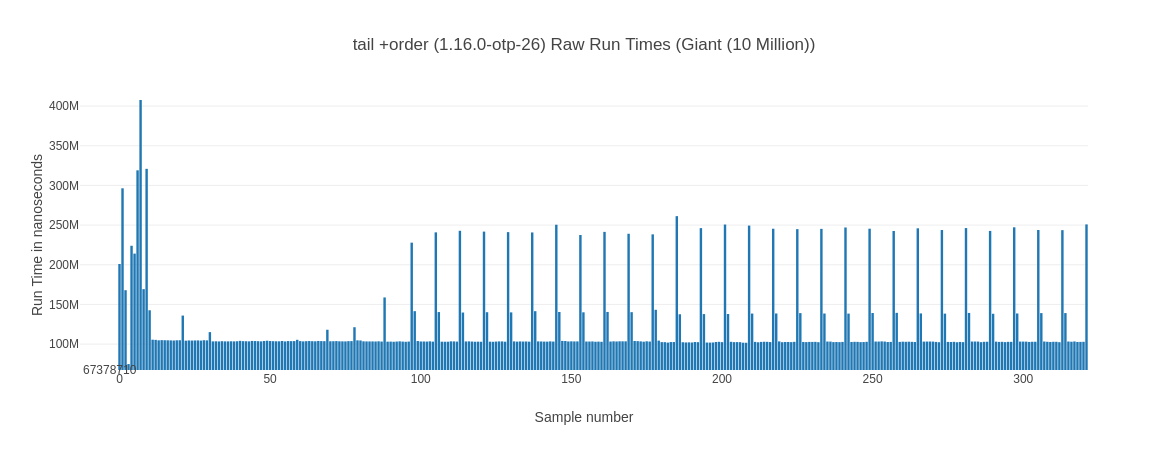
Also tail + order denotes the version that switched the order of the arguments around to pattern match on the first argument, as talked about before when recapping earlier results.
Results
As usual you can peruse the full benchmarking results in the HTML reports or the console output here:
Console Output of the benchmark
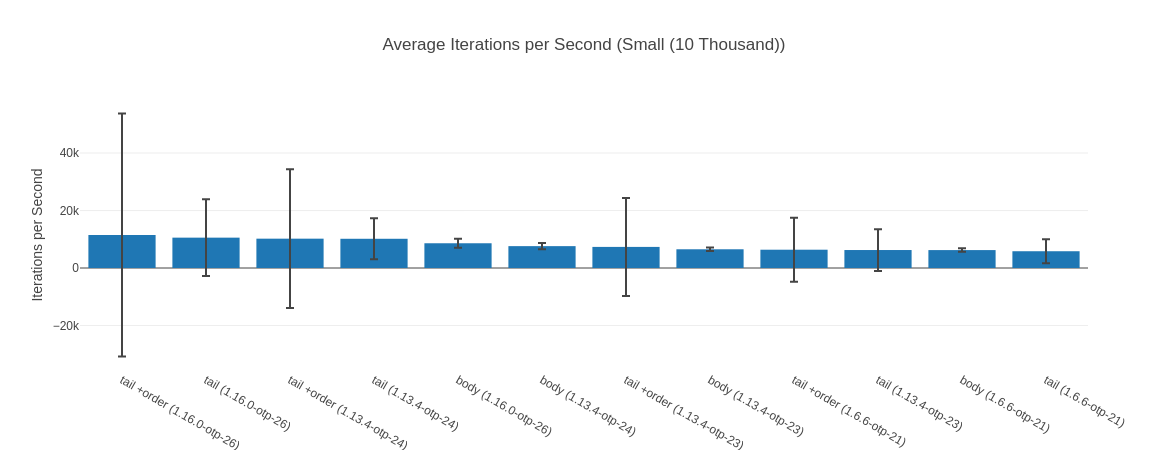
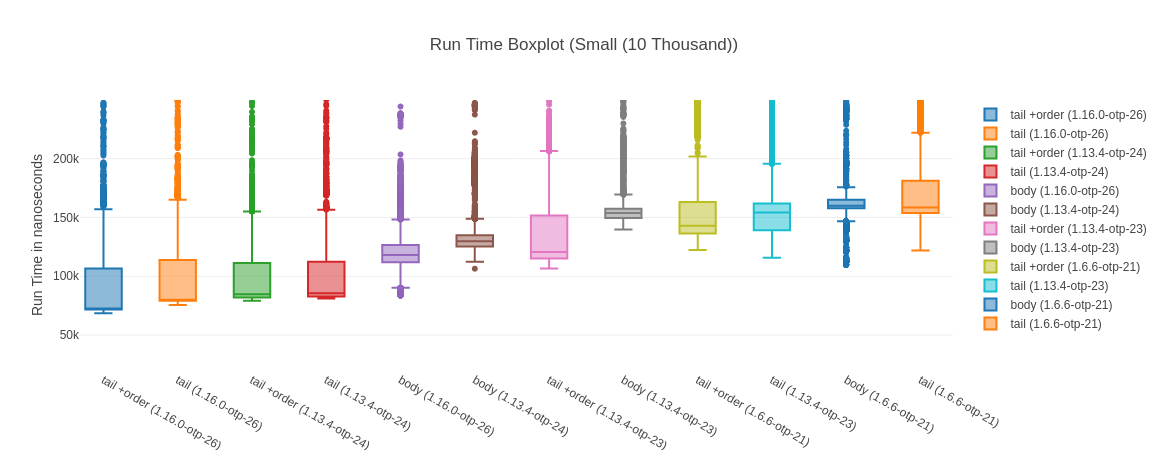
##### With input Small (10 Thousand) #####
Name ips average deviation median 99th %
tail +order (1.16.0-otp-26) 11.48 K 87.10 μs ±368.22% 72.35 μs 131.61 μs
tail (1.16.0-otp-26) 10.56 K 94.70 μs ±126.50% 79.80 μs 139.20 μs
tail +order (1.13.4-otp-24) 10.20 K 98.01 μs ±236.80% 84.80 μs 141.84 μs
tail (1.13.4-otp-24) 10.17 K 98.37 μs ±70.24% 85.55 μs 143.28 μs
body (1.16.0-otp-26) 8.61 K 116.19 μs ±18.37% 118.16 μs 167.50 μs
body (1.13.4-otp-24) 7.60 K 131.50 μs ±13.94% 129.71 μs 192.96 μs
tail +order (1.13.4-otp-23) 7.34 K 136.32 μs ±232.24% 120.61 μs 202.73 μs
body (1.13.4-otp-23) 6.51 K 153.55 μs ±9.75% 153.70 μs 165.62 μs
tail +order (1.6.6-otp-21) 6.36 K 157.14 μs ±175.28% 142.99 μs 240.49 μs
tail (1.13.4-otp-23) 6.25 K 159.92 μs ±116.12% 154.20 μs 253.37 μs
body (1.6.6-otp-21) 6.23 K 160.49 μs ±9.88% 159.88 μs 170.30 μs
tail (1.6.6-otp-21) 5.83 K 171.54 μs ±71.94% 158.44 μs 256.83 μs
Comparison:
tail +order (1.16.0-otp-26) 11.48 K
tail (1.16.0-otp-26) 10.56 K - 1.09x slower +7.60 μs
tail +order (1.13.4-otp-24) 10.20 K - 1.13x slower +10.91 μs
tail (1.13.4-otp-24) 10.17 K - 1.13x slower +11.27 μs
body (1.16.0-otp-26) 8.61 K - 1.33x slower +29.09 μs
body (1.13.4-otp-24) 7.60 K - 1.51x slower +44.40 μs
tail +order (1.13.4-otp-23) 7.34 K - 1.57x slower +49.22 μs
body (1.13.4-otp-23) 6.51 K - 1.76x slower +66.44 μs
tail +order (1.6.6-otp-21) 6.36 K - 1.80x slower +70.04 μs
tail (1.13.4-otp-23) 6.25 K - 1.84x slower +72.82 μs
body (1.6.6-otp-21) 6.23 K - 1.84x slower +73.38 μs
tail (1.6.6-otp-21) 5.83 K - 1.97x slower +84.44 μs
Extended statistics:
Name minimum maximum sample size mode
tail +order (1.16.0-otp-26) 68.68 μs 200466.90 μs 457.09 K 71.78 μs
tail (1.16.0-otp-26) 75.70 μs 64483.82 μs 420.52 K 79.35 μs, 79.36 μs
tail +order (1.13.4-otp-24) 79.22 μs 123986.92 μs 405.92 K 81.91 μs
tail (1.13.4-otp-24) 81.05 μs 41801.49 μs 404.37 K 82.62 μs
body (1.16.0-otp-26) 83.71 μs 5156.24 μs 343.07 K 86.39 μs
body (1.13.4-otp-24) 106.46 μs 5935.86 μs 302.92 K125.90 μs, 125.72 μs, 125
tail +order (1.13.4-otp-23) 106.66 μs 168040.73 μs 292.04 K 109.26 μs
body (1.13.4-otp-23) 139.84 μs 5164.72 μs 259.47 K 147.51 μs
tail +order (1.6.6-otp-21) 122.31 μs 101605.07 μs 253.46 K 138.40 μs
tail (1.13.4-otp-23) 115.74 μs 47040.19 μs 249.14 K 125.40 μs
body (1.6.6-otp-21) 109.67 μs 4938.61 μs 248.26 K 159.82 μs
tail (1.6.6-otp-21) 121.83 μs 40861.21 μs 232.24 K 157.72 μs
Memory usage statistics:
Name Memory usage
tail +order (1.16.0-otp-26) 223.98 KB
tail (1.16.0-otp-26) 223.98 KB - 1.00x memory usage +0 KB
tail +order (1.13.4-otp-24) 223.98 KB - 1.00x memory usage +0 KB
tail (1.13.4-otp-24) 223.98 KB - 1.00x memory usage +0 KB
body (1.16.0-otp-26) 156.25 KB - 0.70x memory usage -67.73438 KB
body (1.13.4-otp-24) 156.25 KB - 0.70x memory usage -67.73438 KB
tail +order (1.13.4-otp-23) 224.02 KB - 1.00x memory usage +0.0313 KB
body (1.13.4-otp-23) 156.25 KB - 0.70x memory usage -67.73438 KB
tail +order (1.6.6-otp-21) 224.03 KB - 1.00x memory usage +0.0469 KB
tail (1.13.4-otp-23) 224.02 KB - 1.00x memory usage +0.0313 KB
body (1.6.6-otp-21) 156.25 KB - 0.70x memory usage -67.73438 KB
tail (1.6.6-otp-21) 224.03 KB - 1.00x memory usage +0.0469 KB
**All measurements for memory usage were the same**
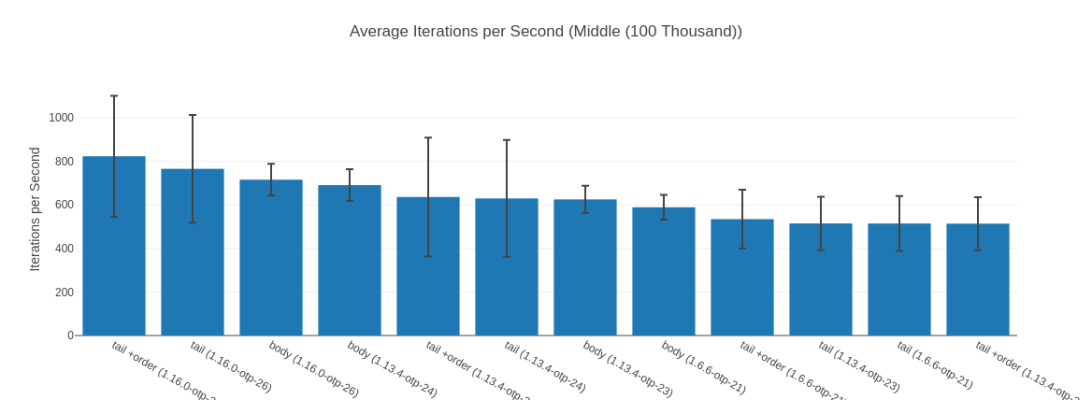
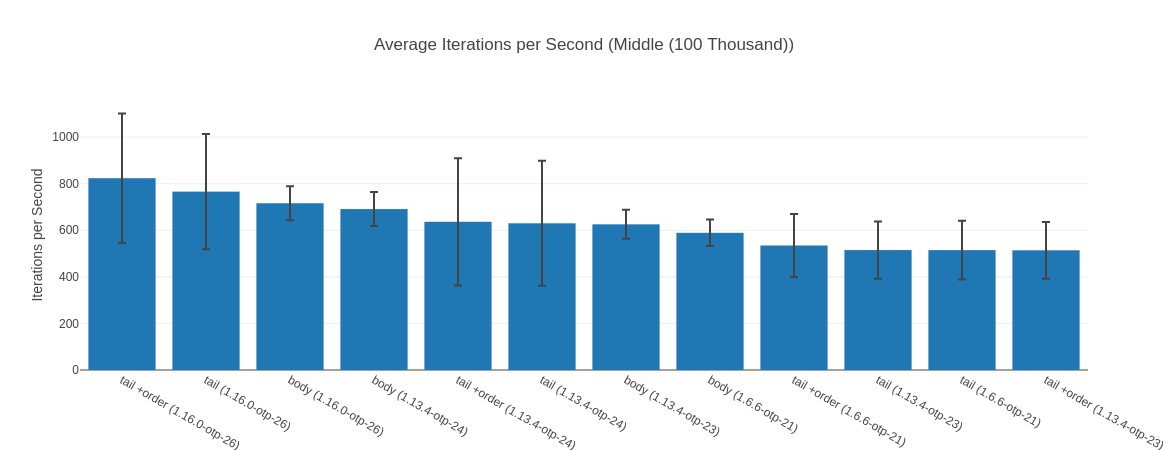
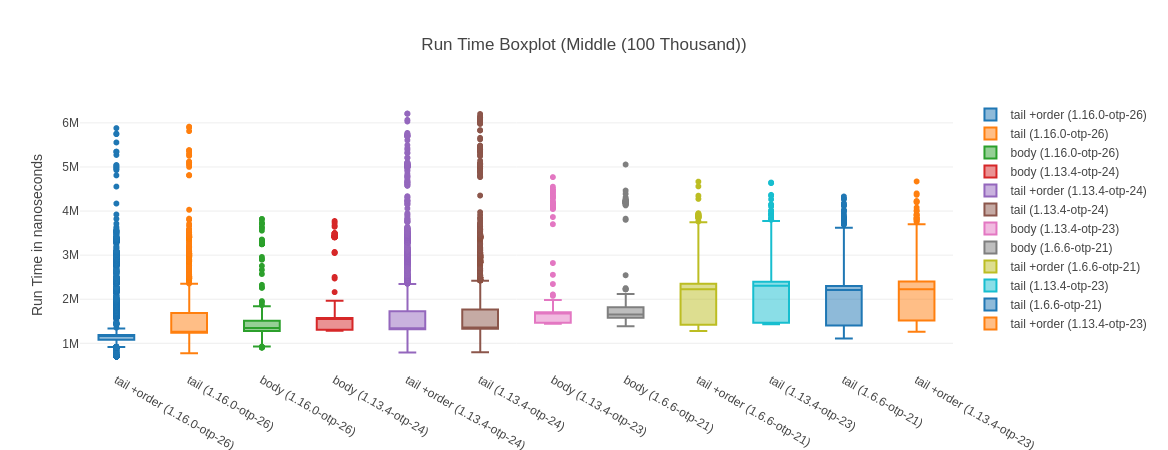
##### With input Middle (100 Thousand) #####
Name ips average deviation median 99th %
tail +order (1.16.0-otp-26) 823.46 1.21 ms ±33.74% 1.17 ms 2.88 ms
tail (1.16.0-otp-26) 765.87 1.31 ms ±32.35% 1.25 ms 2.99 ms
body (1.16.0-otp-26) 715.86 1.40 ms ±10.19% 1.35 ms 1.57 ms
body (1.13.4-otp-24) 690.92 1.45 ms ±10.57% 1.56 ms 1.64 ms
tail +order (1.13.4-otp-24) 636.45 1.57 ms ±42.91% 1.33 ms 3.45 ms
tail (1.13.4-otp-24) 629.78 1.59 ms ±42.61% 1.36 ms 3.45 ms
body (1.13.4-otp-23) 625.42 1.60 ms ±9.95% 1.68 ms 1.79 ms
body (1.6.6-otp-21) 589.10 1.70 ms ±9.69% 1.65 ms 1.92 ms
tail +order (1.6.6-otp-21) 534.56 1.87 ms ±25.30% 2.22 ms 2.44 ms
tail (1.13.4-otp-23) 514.88 1.94 ms ±23.90% 2.31 ms 2.47 ms
tail (1.6.6-otp-21) 514.64 1.94 ms ±24.51% 2.21 ms 2.71 ms
tail +order (1.13.4-otp-23) 513.89 1.95 ms ±23.73% 2.23 ms 2.47 ms
Comparison:
tail +order (1.16.0-otp-26) 823.46
tail (1.16.0-otp-26) 765.87 - 1.08x slower +0.0913 ms
body (1.16.0-otp-26) 715.86 - 1.15x slower +0.183 ms
body (1.13.4-otp-24) 690.92 - 1.19x slower +0.23 ms
tail +order (1.13.4-otp-24) 636.45 - 1.29x slower +0.36 ms
tail (1.13.4-otp-24) 629.78 - 1.31x slower +0.37 ms
body (1.13.4-otp-23) 625.42 - 1.32x slower +0.38 ms
body (1.6.6-otp-21) 589.10 - 1.40x slower +0.48 ms
tail +order (1.6.6-otp-21) 534.56 - 1.54x slower +0.66 ms
tail (1.13.4-otp-23) 514.88 - 1.60x slower +0.73 ms
tail (1.6.6-otp-21) 514.64 - 1.60x slower +0.73 ms
tail +order (1.13.4-otp-23) 513.89 - 1.60x slower +0.73 ms
Extended statistics:
Name minimum maximum sample size mode
tail +order (1.16.0-otp-26) 0.70 ms 5.88 ms 32.92 K 0.71 ms
tail (1.16.0-otp-26) 0.77 ms 5.91 ms 30.62 K 0.78 ms
body (1.16.0-otp-26) 0.90 ms 3.82 ms 28.62 K 1.51 ms, 1.28 ms
body (1.13.4-otp-24) 1.29 ms 3.77 ms 27.62 K 1.30 ms, 1.31 ms
tail +order (1.13.4-otp-24) 0.79 ms 6.21 ms 25.44 K1.32 ms, 1.32 ms, 1.32 ms
tail (1.13.4-otp-24) 0.80 ms 6.20 ms 25.18 K 1.36 ms
body (1.13.4-otp-23) 1.44 ms 4.77 ms 25.00 K 1.45 ms, 1.45 ms
body (1.6.6-otp-21) 1.39 ms 5.06 ms 23.55 K 1.64 ms
tail +order (1.6.6-otp-21) 1.28 ms 4.67 ms 21.37 K 1.42 ms
tail (1.13.4-otp-23) 1.43 ms 4.65 ms 20.59 K 1.44 ms, 1.44 ms
tail (1.6.6-otp-21) 1.11 ms 4.33 ms 20.58 K 1.40 ms
tail +order (1.13.4-otp-23) 1.26 ms 4.67 ms 20.55 K 1.52 ms
Memory usage statistics:
Name Memory usage
tail +order (1.16.0-otp-26) 2.90 MB
tail (1.16.0-otp-26) 2.90 MB - 1.00x memory usage +0 MB
body (1.16.0-otp-26) 1.53 MB - 0.53x memory usage -1.37144 MB
body (1.13.4-otp-24) 1.53 MB - 0.53x memory usage -1.37144 MB
tail +order (1.13.4-otp-24) 2.93 MB - 1.01x memory usage +0.0354 MB
tail (1.13.4-otp-24) 2.93 MB - 1.01x memory usage +0.0354 MB
body (1.13.4-otp-23) 1.53 MB - 0.53x memory usage -1.37144 MB
body (1.6.6-otp-21) 1.53 MB - 0.53x memory usage -1.37144 MB
tail +order (1.6.6-otp-21) 2.89 MB - 1.00x memory usage -0.00793 MB
tail (1.13.4-otp-23) 2.89 MB - 1.00x memory usage -0.01099 MB
tail (1.6.6-otp-21) 2.89 MB - 1.00x memory usage -0.00793 MB
tail +order (1.13.4-otp-23) 2.89 MB - 1.00x memory usage -0.01099 MB
**All measurements for memory usage were the same**
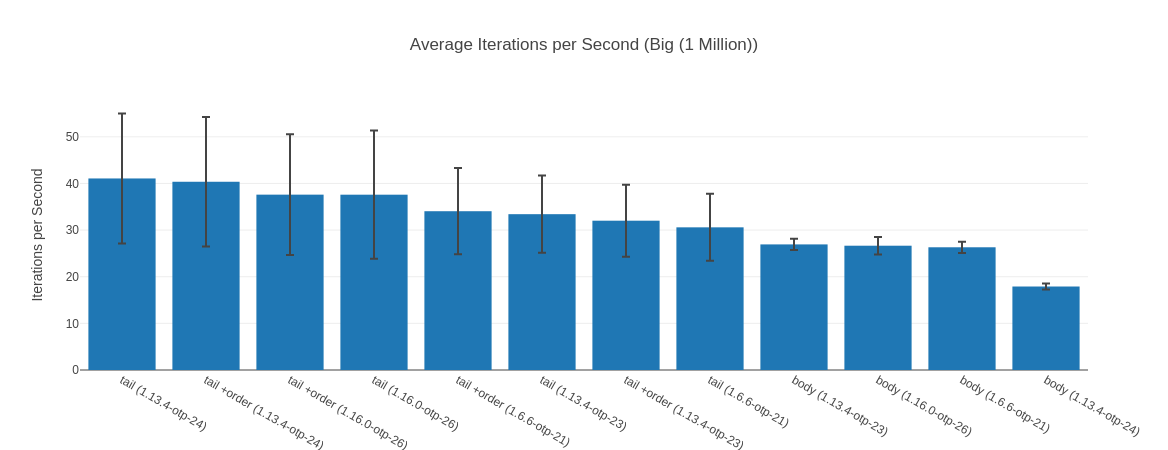
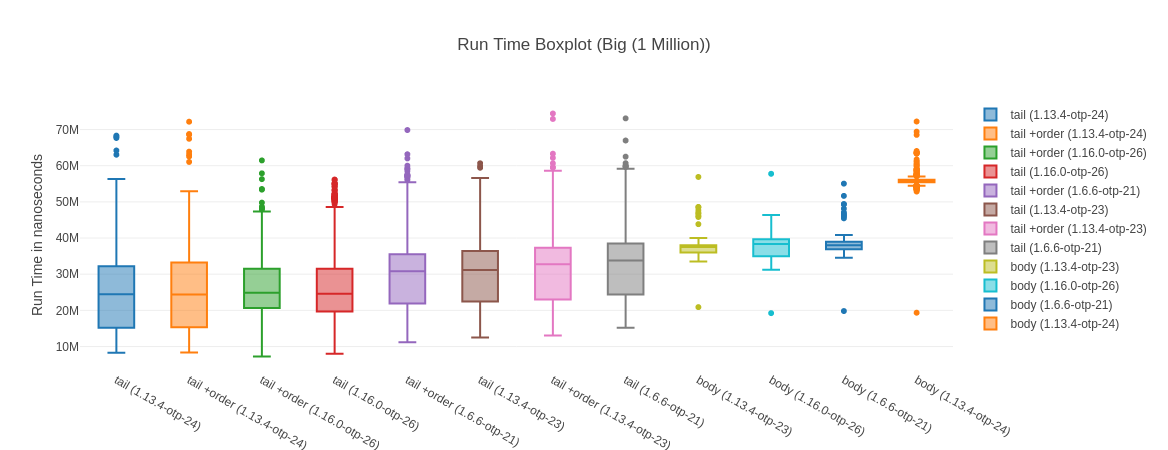
##### With input Big (1 Million) #####
Name ips average deviation median 99th %
tail (1.13.4-otp-24) 41.07 24.35 ms ±33.92% 24.44 ms 47.47 ms
tail +order (1.13.4-otp-24) 40.37 24.77 ms ±34.43% 24.40 ms 48.88 ms
tail +order (1.16.0-otp-26) 37.60 26.60 ms ±34.40% 24.86 ms 46.90 ms
tail (1.16.0-otp-26) 37.59 26.60 ms ±36.56% 24.57 ms 52.22 ms
tail +order (1.6.6-otp-21) 34.05 29.37 ms ±27.14% 30.79 ms 56.63 ms
tail (1.13.4-otp-23) 33.41 29.93 ms ±24.80% 31.17 ms 50.95 ms
tail +order (1.13.4-otp-23) 32.01 31.24 ms ±24.13% 32.78 ms 56.27 ms
tail (1.6.6-otp-21) 30.59 32.69 ms ±23.49% 33.78 ms 59.07 ms
body (1.13.4-otp-23) 26.93 37.13 ms ±4.54% 37.51 ms 39.63 ms
body (1.16.0-otp-26) 26.65 37.52 ms ±7.09% 38.36 ms 41.84 ms
body (1.6.6-otp-21) 26.32 38.00 ms ±4.56% 38.02 ms 43.01 ms
body (1.13.4-otp-24) 17.90 55.86 ms ±3.63% 55.74 ms 63.59 ms
Comparison:
tail (1.13.4-otp-24) 41.07
tail +order (1.13.4-otp-24) 40.37 - 1.02x slower +0.43 ms
tail +order (1.16.0-otp-26) 37.60 - 1.09x slower +2.25 ms
tail (1.16.0-otp-26) 37.59 - 1.09x slower +2.25 ms
tail +order (1.6.6-otp-21) 34.05 - 1.21x slower +5.02 ms
tail (1.13.4-otp-23) 33.41 - 1.23x slower +5.58 ms
tail +order (1.13.4-otp-23) 32.01 - 1.28x slower +6.89 ms
tail (1.6.6-otp-21) 30.59 - 1.34x slower +8.34 ms
body (1.13.4-otp-23) 26.93 - 1.53x slower +12.79 ms
body (1.16.0-otp-26) 26.65 - 1.54x slower +13.17 ms
body (1.6.6-otp-21) 26.32 - 1.56x slower +13.65 ms
body (1.13.4-otp-24) 17.90 - 2.29x slower +31.51 ms
Extended statistics:
Name minimum maximum sample size mode
tail (1.13.4-otp-24) 8.31 ms 68.32 ms 1.64 K None
tail +order (1.13.4-otp-24) 8.36 ms 72.16 ms 1.62 K 33.33 ms, 15.15 ms
tail +order (1.16.0-otp-26) 7.25 ms 61.46 ms 1.50 K 26.92 ms
tail (1.16.0-otp-26) 8.04 ms 56.17 ms 1.50 K None
tail +order (1.6.6-otp-21) 11.20 ms 69.86 ms 1.36 K 37.39 ms
tail (1.13.4-otp-23) 12.47 ms 60.67 ms 1.34 K None
tail +order (1.13.4-otp-23) 13.06 ms 74.43 ms 1.28 K 23.27 ms
tail (1.6.6-otp-21) 15.17 ms 73.09 ms 1.22 K None
body (1.13.4-otp-23) 20.90 ms 56.89 ms 1.08 K 38.11 ms
body (1.16.0-otp-26) 19.23 ms 57.76 ms 1.07 K None
body (1.6.6-otp-21) 19.81 ms 55.04 ms 1.05 K None
body (1.13.4-otp-24) 19.36 ms 72.21 ms 716 None
Memory usage statistics:
Name Memory usage
tail (1.13.4-otp-24) 26.95 MB
tail +order (1.13.4-otp-24) 26.95 MB - 1.00x memory usage +0 MB
tail +order (1.16.0-otp-26) 26.95 MB - 1.00x memory usage +0.00015 MB
tail (1.16.0-otp-26) 26.95 MB - 1.00x memory usage +0.00015 MB
tail +order (1.6.6-otp-21) 26.95 MB - 1.00x memory usage +0.00031 MB
tail (1.13.4-otp-23) 26.95 MB - 1.00x memory usage +0.00029 MB
tail +order (1.13.4-otp-23) 26.95 MB - 1.00x memory usage +0.00029 MB
tail (1.6.6-otp-21) 26.95 MB - 1.00x memory usage +0.00031 MB
body (1.13.4-otp-23) 15.26 MB - 0.57x memory usage -11.69537 MB
body (1.16.0-otp-26) 15.26 MB - 0.57x memory usage -11.69537 MB
body (1.6.6-otp-21) 15.26 MB - 0.57x memory usage -11.69537 MB
body (1.13.4-otp-24) 15.26 MB - 0.57x memory usage -11.69537 MB
**All measurements for memory usage were the same**
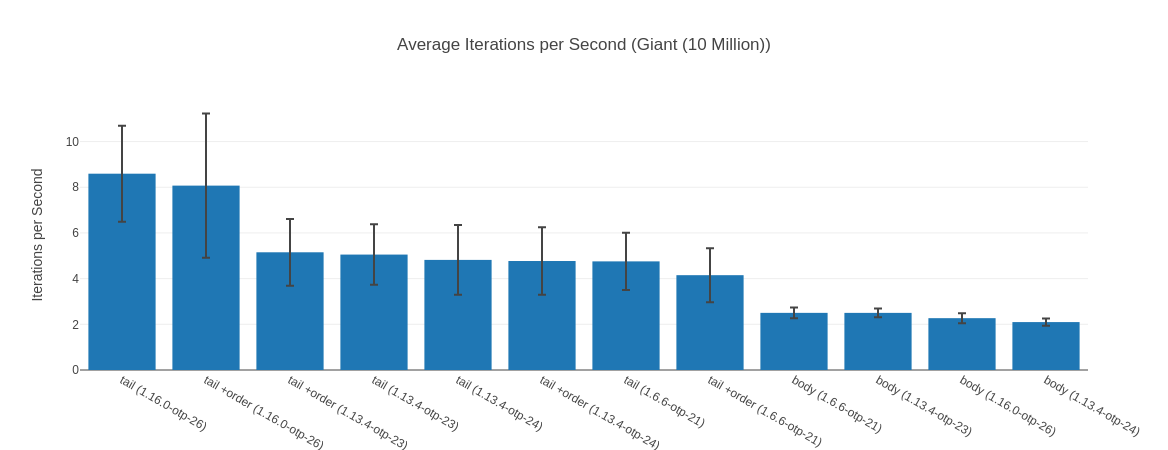
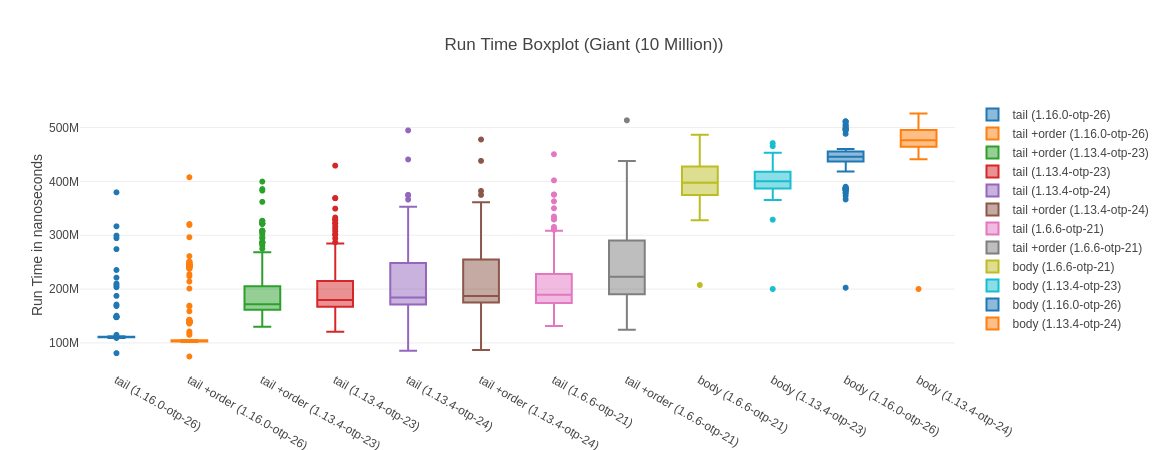
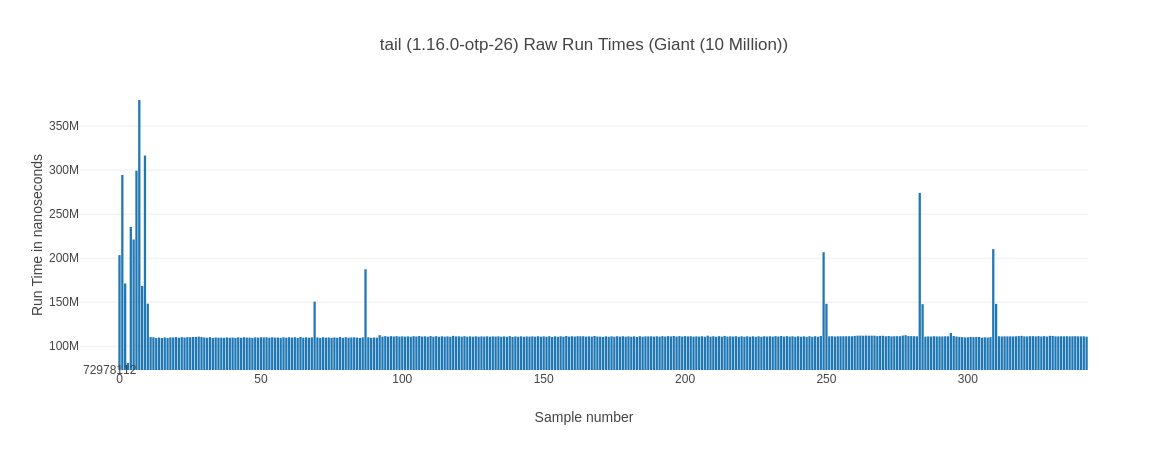
##### With input Giant (10 Million) #####
Name ips average deviation median 99th %
tail (1.16.0-otp-26) 8.59 116.36 ms ±24.44% 111.06 ms 297.27 ms
tail +order (1.16.0-otp-26) 8.07 123.89 ms ±39.11% 103.42 ms 313.82 ms
tail +order (1.13.4-otp-23) 5.15 194.07 ms ±28.32% 171.83 ms 385.56 ms
tail (1.13.4-otp-23) 5.05 197.91 ms ±26.21% 179.95 ms 368.95 ms
tail (1.13.4-otp-24) 4.82 207.47 ms ±31.62% 184.35 ms 444.05 ms
tail +order (1.13.4-otp-24) 4.77 209.59 ms ±31.01% 187.04 ms 441.28 ms
tail (1.6.6-otp-21) 4.76 210.30 ms ±26.31% 189.71 ms 406.29 ms
tail +order (1.6.6-otp-21) 4.15 240.89 ms ±28.46% 222.87 ms 462.93 ms
body (1.6.6-otp-21) 2.50 399.78 ms ±9.42% 397.69 ms 486.53 ms
body (1.13.4-otp-23) 2.50 399.88 ms ±7.58% 400.23 ms 471.07 ms
body (1.16.0-otp-26) 2.27 440.73 ms ±9.60% 445.77 ms 511.66 ms
body (1.13.4-otp-24) 2.10 476.77 ms ±7.72% 476.57 ms 526.09 ms
Comparison:
tail (1.16.0-otp-26) 8.59
tail +order (1.16.0-otp-26) 8.07 - 1.06x slower +7.53 ms
tail +order (1.13.4-otp-23) 5.15 - 1.67x slower +77.71 ms
tail (1.13.4-otp-23) 5.05 - 1.70x slower +81.55 ms
tail (1.13.4-otp-24) 4.82 - 1.78x slower +91.11 ms
tail +order (1.13.4-otp-24) 4.77 - 1.80x slower +93.23 ms
tail (1.6.6-otp-21) 4.76 - 1.81x slower +93.94 ms
tail +order (1.6.6-otp-21) 4.15 - 2.07x slower +124.53 ms
body (1.6.6-otp-21) 2.50 - 3.44x slower +283.42 ms
body (1.13.4-otp-23) 2.50 - 3.44x slower +283.52 ms
body (1.16.0-otp-26) 2.27 - 3.79x slower +324.37 ms
body (1.13.4-otp-24) 2.10 - 4.10x slower +360.41 ms
Extended statistics:
Name minimum maximum sample size mode
tail (1.16.0-otp-26) 81.09 ms 379.73 ms 343 None
tail +order (1.16.0-otp-26) 74.87 ms 407.68 ms 322 None
tail +order (1.13.4-otp-23) 129.96 ms 399.67 ms 206 None
tail (1.13.4-otp-23) 120.60 ms 429.31 ms 203 None
tail (1.13.4-otp-24) 85.42 ms 494.75 ms 193 None
tail +order (1.13.4-otp-24) 86.99 ms 477.82 ms 191 None
tail (1.6.6-otp-21) 131.60 ms 450.47 ms 190 224.04 ms
tail +order (1.6.6-otp-21) 124.69 ms 513.50 ms 166 None
body (1.6.6-otp-21) 207.61 ms 486.65 ms 100 None
body (1.13.4-otp-23) 200.16 ms 471.13 ms 100 None
body (1.16.0-otp-26) 202.63 ms 511.66 ms 91 None
body (1.13.4-otp-24) 200.17 ms 526.09 ms 84 None
Memory usage statistics:
Name Memory usage
tail (1.16.0-otp-26) 303.85 MB
tail +order (1.16.0-otp-26) 303.85 MB - 1.00x memory usage +0 MB
tail +order (1.13.4-otp-23) 303.79 MB - 1.00x memory usage -0.06104 MB
tail (1.13.4-otp-23) 303.79 MB - 1.00x memory usage -0.06104 MB
tail (1.13.4-otp-24) 301.64 MB - 0.99x memory usage -2.21191 MB
tail +order (1.13.4-otp-24) 301.64 MB - 0.99x memory usage -2.21191 MB
tail (1.6.6-otp-21) 303.77 MB - 1.00x memory usage -0.07690 MB
tail +order (1.6.6-otp-21) 303.77 MB - 1.00x memory usage -0.07690 MB
body (1.6.6-otp-21) 152.59 MB - 0.50x memory usage -151.25967 MB
body (1.13.4-otp-23) 152.59 MB - 0.50x memory usage -151.25967 MB
body (1.16.0-otp-26) 152.59 MB - 0.50x memory usage -151.25967 MB
body (1.13.4-otp-24) 152.59 MB - 0.50x memory usage -151.25967 MB
**All measurements for memory usage were the same**
##### With input Titanic (50 Million) #####
Name ips average deviation median 99th %
tail (1.13.4-otp-24) 0.85 1.18 s ±26.26% 1.11 s 2.00 s
tail +order (1.16.0-otp-26) 0.85 1.18 s ±28.67% 1.21 s 1.91 s
tail (1.16.0-otp-26) 0.84 1.18 s ±28.05% 1.18 s 1.97 s
tail +order (1.13.4-otp-24) 0.82 1.22 s ±27.20% 1.13 s 2.04 s
tail (1.13.4-otp-23) 0.79 1.26 s ±24.44% 1.25 s 1.88 s
tail +order (1.13.4-otp-23) 0.79 1.27 s ±22.64% 1.26 s 1.93 s
tail +order (1.6.6-otp-21) 0.76 1.32 s ±17.39% 1.37 s 1.83 s
tail (1.6.6-otp-21) 0.75 1.33 s ±18.22% 1.39 s 1.86 s
body (1.6.6-otp-21) 0.58 1.73 s ±15.01% 1.83 s 2.23 s
body (1.13.4-otp-23) 0.55 1.81 s ±19.33% 1.90 s 2.25 s
body (1.16.0-otp-26) 0.53 1.88 s ±16.13% 1.96 s 2.38 s
body (1.13.4-otp-24) 0.44 2.28 s ±17.61% 2.46 s 2.58 s
Comparison:
tail (1.13.4-otp-24) 0.85
tail +order (1.16.0-otp-26) 0.85 - 1.00x slower +0.00085 s
tail (1.16.0-otp-26) 0.84 - 1.01x slower +0.00803 s
tail +order (1.13.4-otp-24) 0.82 - 1.04x slower +0.0422 s
tail (1.13.4-otp-23) 0.79 - 1.07x slower +0.0821 s
tail +order (1.13.4-otp-23) 0.79 - 1.08x slower +0.0952 s
tail +order (1.6.6-otp-21) 0.76 - 1.12x slower +0.145 s
tail (1.6.6-otp-21) 0.75 - 1.13x slower +0.152 s
body (1.6.6-otp-21) 0.58 - 1.47x slower +0.55 s
body (1.13.4-otp-23) 0.55 - 1.54x slower +0.63 s
body (1.16.0-otp-26) 0.53 - 1.59x slower +0.70 s
body (1.13.4-otp-24) 0.44 - 1.94x slower +1.10 s
Extended statistics:
Name minimum maximum sample size mode
tail (1.13.4-otp-24) 0.84 s 2.00 s 34 None
tail +order (1.16.0-otp-26) 0.38 s 1.91 s 34 None
tail (1.16.0-otp-26) 0.41 s 1.97 s 34 None
tail +order (1.13.4-otp-24) 0.83 s 2.04 s 33 None
tail (1.13.4-otp-23) 0.73 s 1.88 s 32 None
tail +order (1.13.4-otp-23) 0.71 s 1.93 s 32 None
tail +order (1.6.6-otp-21) 0.87 s 1.83 s 31 None
tail (1.6.6-otp-21) 0.90 s 1.86 s 30 None
body (1.6.6-otp-21) 0.87 s 2.23 s 24 None
body (1.13.4-otp-23) 0.85 s 2.25 s 22 None
body (1.16.0-otp-26) 1.00 s 2.38 s 22 None
body (1.13.4-otp-24) 1.02 s 2.58 s 18 None
Memory usage statistics:
Name Memory usage
tail (1.13.4-otp-24) 1.49 GB
tail +order (1.16.0-otp-26) 1.49 GB - 1.00x memory usage -0.00085 GB
tail (1.16.0-otp-26) 1.49 GB - 1.00x memory usage -0.00085 GB
tail +order (1.13.4-otp-24) 1.49 GB - 1.00x memory usage +0 GB
tail (1.13.4-otp-23) 1.49 GB - 1.00x memory usage +0.00161 GB
tail +order (1.13.4-otp-23) 1.49 GB - 1.00x memory usage +0.00161 GB
tail +order (1.6.6-otp-21) 1.49 GB - 1.00x memory usage +0.00151 GB
tail (1.6.6-otp-21) 1.49 GB - 1.00x memory usage +0.00151 GB
body (1.6.6-otp-21) 0.75 GB - 0.50x memory usage -0.74222 GB
body (1.13.4-otp-23) 0.75 GB - 0.50x memory usage -0.74222 GB
body (1.16.0-otp-26) 0.75 GB - 0.50x memory usage -0.74222 GB
body (1.13.4-otp-24) 0.75 GB - 0.50x memory usage -0.74222 GB
So, what are our key findings?
Tail-Recursive Functions with Elixir 1.16 @ OTP 26.2 are fastest
For all but one input elixir 1.16 @ OTP 26.2 is the fastest implementation or virtually tied with the fastest implementation. It’s great to know that our most recent version brings us some speed goodies!
Is that the impact of the JIT you may ask? It can certainly seem so – when we’re looking at the list with 10 000 elements as input we see that even the slowest JIT implementation is faster than the fastest non-JIT implementation (remember, the JIT was introduced in OTP 24):
You can see the standard deviation here can be quite high, which is “thanks” to a few outliers that make the boxplot almost unreadable. Noise from Garbage Collection is often a bit of a problem with micro-benchmarks, but the results are stable and the sample size big enough. Here is a highly zoomed in boxplot to make it readable:
What’s really impressive to me is that the fastest version is 57% faster than the fastest non JIT version (tail +order (1.16.0-otp-26) vs. tail +order (1.13.4-otp-23)). Of course, this is a very specific benchmark and may not be indicative of overall performance gains – it’s impressive nonetheless. The other good sign is that we seem to be continuing to improve, as our current best version is 13% faster than anything available on our other most recent platform (1.13 @ OTP 24.3).
The performance uplift of Elixir 1.16 running on OTP 26.2 is even more impressive when we look at the input list of 100k elements – where all its map implementations take the 3 top spots:
Here the speedup of “fastest JIT vs. fastest non JIT” is still a great 40%. Interestingly here though, for all versions except for Elixir 1.16.0 on OTP 26.2 the body-recursive functions are faster than their tail-recursive counter parts. Hold that thought for later, let’s first take a look a weird outlier – the input list with 1 Million elements.
The Outlier Input – 1 Million
So, why is that the outlier? Well, here Elixir 1.13 on OTP 24.3 is faster than Elixir 1.16 on OTP 26.2! Maybe we just got unlucky you may think, but I have reproduced this result over many different runs of this benchmark. The lead also goes away again with an input list of 10 Million. Now, you may say “Tobi, we shouldn’t be dealing with lists of 1 Million and up elements anyhow” and I’d agree with you. Humor me though, as I find it fascinating what a huge impact inputs can have as well as how “random” they are. At 100k and 10 Million our Elixir 1.16 is fastest, but somehow for 1 Million it isn’t? I have no idea why, but it seems legit.
Before we dig in, it’s interesting to notice that at the 1 Million inputs mark, the body-recursive functions together occupy the last 4 spots of our ranking. It stays like this for all bigger inputs.
When I look at a result that is “weird” to me I usually look at a bunch of other statistical values: 99th%, median, standard deviation, maximum etc. to see if maybe there were some weird outliers here. Specifically I’m checking whether the medians roughly line up with the averages in their ordering – which they do here. Everything seems fine here.
The next thing I’m looking are the raw recorded run times (in order) as well as their general distribution. While looking at those you can notice some interesting behavior. While both elixir 1.13 @ OTP 24.3 solutions have a more or less steady pattern to their run times, their elixir 1.16 @ OTP 26.2 counter parts seem to experience a noticeable slow down towards the last ~15% of their measurement time. Let’s look at 2 examples for the the tail +order variants:
Why is this happening? I don’t know – you could blame it on on some background job or something kicking in but then it wouldn’t be consistent across tail and tail +order for the elixir 1.16 variant. While we’re looking at these graphs, what about the bod-recursive cousin?
Less Deviation for Body-Recursive Functions
The body-recursive version looks a lot smoother and less jittery. This is something you can observe across all inputs – as indicated by the much lower standard-deviation of body-recursive implementations.
Memory Consumption
The memory consumption story is much less interesting – body-recursive functions consume less memory and by quite the margin! ~50% of the tail-recursive functions for all but our smallest input size – there it’s still 70%.
This might also be one of the key to seeing less jittery run times – less memory means less garbage produced means fewer garbage collection runs necessary.
A 60%+ lead – the 10 Million Input
What I found interesting looking at the results is that for our 10 Million input elixir 1.16 @ OTP 26 is 67% faster than the next fastest implementation. Which is a huge difference.
We also see that the tail-recursive solution here is almost 4 times as fast as the body-recursive version. Somewhat interestingly the version without the argument order switch seems faster here (but not by much). You can also see that the median is (considerably) in favor of tail +order against its just tail counter part.
Let’s take another look at our new found friend – the raw run times chart:
We can clearly see that the tail +order version goes into a repeating pattern of taking much longer every couple of runs while the tail version is (mostly) stable. That explains the lower average while it has a higher median for the tail version. It is faster on average by being more consistent – so while its median is slightly worse it is on average faster as it doesn’t exhibit these spikes. Why is this happening? I don’t know, except that I know I’ve seen it more than once.
And now? For Elixir 1.16 on OTP 26.2 the tail-recursive functions are faster than their body-recursive counter part on all tested inputs! How different depends on the input size – from just 15% to almost 400% we’ve seen it all.
This is also a “fairly recent” development – for instance for our 100k input for Elixir 1.13@OTP 24 the body-recursive function is the fastest.
Naturally that still doesn’t mean everything should be tail-recursive: This is one benchmark with list sizes you may rarely see. Memory consumption and variance are also points to consider. Also let’s remember a quote from “The Seven Myths of Erlang Performance” about this:
It is generally not possible to predict whether the tail-recursive or the body-recursive version will be faster. Therefore, use the version that makes your code cleaner (hint: it is usually the body-recursive version).
And of course, some use cases absolutely need a tail-recursive function (such as Genservers).
Finishing Up
So, what have we discovered? On our newest Elixir and Erlang versions tail-recursive functions shine more than they did before – outperforming the competition. We have seen some impressive performance improvements over time, presumably thanks to the JIT – and we seem to be getting even more performance improvements.
As always, run your own benchmarks – don’t trust some old post on the Internet saying one thing is faster than another. Your compiler, your run time – things may have changed.
Lastly, I’m happy to finally publish these results – it’s been a bit of a yakshave. But, a fun one! 😁
As per usual you can check out the official Changelog for what exactly happened. This is a more personal look, featuring both the highlights of the release and some more musings.
The highlights are:
Vastly reduced memory usage when benchmarking with big inputs
New Benchee.report/1 to simplify working with saved benchmarks
finally configured times will be shown in a human compatible format
So let’s dig in a bit.
How did this release happen?
I didn’t want to release a new benchee version so soon. What happened is I sat down to write a huge benchmark and you can check out this handy list for what transpired going on from there:
1. Write huge benchmark 2. Fix missing ergonomics in benchee 3. memory consumption high, investigate 4. Implement new feature as fix 5. Realize it was the wrong fix, worked by accident 6. Fix real issue 7. Blog about issue cos 🤦♂️ (see post) 8. Remove now unneeded feature as it doesn’t fix it 9. Release new benchee version <— we are here 10. Write actual benchmark
So… we’re close to me blogging about that benchmark 😅 Maybe… next week?
And I mean that’s fine and fun – one of the biggest reasons why benchee exists is because I love writing benchmarks and benchee is here to make that (along with blogging about it) as easy, seamless and friction-less as possible. So, me pushing the boundaries of benchee and making it better in the process is working as intended.
How big are those memory savings?
To put it into context the benchmark I’m working on, has 3 functions and 4 inputs (10k list –> 10M list) – so 12 scenarios in total. This is then run on 4 different elixir x erlang combinations – totaling 48 scenarios.
The changes on the 1.3 branch had the following impact:
Memory consumption for an individual run (12 scenarios, saving them) went from ~6.5 GByte to ~5.1 GByte – saving more than 20%.
The size of saving the results of one run went from ~226MB to ~4MB. That is with a long benchmarking time, decreasing it to 10 seconds we’re looking at ~223MB down to 1MB.
Before the change creating the report (all 48 scenarios) took between 12.8 GB and 18.6GB (average ~15.3 GB). Afterwards? 1.8 GB – a reduction down to ~12%.
The time it takes to create the report also went from ~18 seconds to ~3.4 seconds, more than 5 times as fast.
So, while I’m still 🤦♂ that this was ever an issue, I’m also happy about the fix and shipping those changes to you. I go more into what the actual issue was and how it was fixed in my previous post.
Downsides of the change
At its heart the change that enabled this is just “stop sending inputs and benchmarking functions into other processes when they are not needed” – which is reasonable, I know statistics calculation does not need access and formatters should not need access. However, it is still a breaking change for formatter plugins which I generally don’t want to put onto people – but in this case in my head it’s a bug. This data was never intended to be available there – it was a pure oversight of mine due to magic.
The feature that never was
As perhaps a fun anecdote, during the (short) 1.3 development period I implemented and removed an entire feature. The short of it is that when I ran into the outrageous memory consumption problems, I first thought it was (in part) due to formatters being executed in parallel and so holding too much memory in memory. I implemented a new function sequential_output that allowed formatting a something and immediately writing it out. This was opposed to how benchee generally works – first formatting everything, and then writing it out.
And… it worked! Memory consumption was down – but how? Well, when running it I didn’t execute it in a separate process – hence the data copying issue never occurred. It worked by accident.
Thankfully I ran a benchmark and put it head to head against format and write – both without processes around – and was shocked to find out that they were the same performance wise. So… that’s how I started to see that the actual problem was launching the extra processes and copying the data to them.
In the end, that feature didn’t provide enough upside any more to justify its existence. You can say goodbye to it here.
Closing
With that, all that’s left to say is: Hope you’re doing well, always benchmark and happy holidays! 🌟
In Elixir and on the BEAM (Erlang Virtual Machine) in general we love our processes – lightweight, easily run millions of them, easy lock-less parallelism – you’ve probably heard it all. Processes are great and one of the many reasons people gravitate towards the BEAM.
Functions like Task.async/1 make parallelism effortless and can feel almost magical. Cool, let’s use it in a simple benchmark! Let’s create some random lists, and then let’s run some non trivial Enum functions on them: uniq, frequencies and shuffle and let’s compare doing them sequentially (one after the other) and running them all in parallel. This kind of work is super easy to parallelize, so we can just fire off the tasks and then await them:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Cool, let’s check out the results! You can check the HTML report online here, uncollapse for the console formatter version or just check out the pictures.
Console formatter output
Operating System: Linux
CPU Information: AMD Ryzen 9 5900X 12-Core Processor
Number of Available Cores: 24
Available memory: 31.25 GB
Elixir 1.16.0-rc.1
Erlang 26.1.2
JIT enabled: true
Benchmark suite executing with the following configuration:
warmup: 15 s
time: 1 min
memory time: 0 ns
reduction time: 0 ns
parallel: 1
inputs: 10k, 1M, 10M
Estimated total run time: 7.50 min
##### With input 10k #####
Name ips average deviation median 99th %
sequential 315.29 3.17 ms ±20.76% 2.96 ms 5.44 ms
parallel 156.77 6.38 ms ±31.08% 6.11 ms 10.75 ms
Comparison:
sequential 315.29
parallel 156.77 - 2.01x slower +3.21 ms
Extended statistics:
Name minimum maximum sample size mode
sequential 2.61 ms 7.84 ms 18.91 K 2.73 ms, 3.01 ms
parallel 3.14 ms 11.99 ms 9.40 K4.80 ms, 4.87 ms, 8.93 ms
##### With input 1M #####
Name ips average deviation median 99th %
sequential 1.14 0.87 s ±7.16% 0.88 s 0.99 s
parallel 0.94 1.07 s ±3.65% 1.07 s 1.16 s
Comparison:
sequential 1.14
parallel 0.94 - 1.22x slower +0.194 s
Extended statistics:
Name minimum maximum sample size mode
sequential 0.74 s 0.99 s 69 None
parallel 0.98 s 1.16 s 57 None
##### With input 10M #####
Name ips average deviation median 99th %
sequential 0.0896 11.17 s ±10.79% 11.21 s 12.93 s
parallel 0.0877 11.40 s ±1.70% 11.37 s 11.66 s
Comparison:
sequential 0.0896
parallel 0.0877 - 1.02x slower +0.23 s
Extended statistics:
Name minimum maximum sample size mode
sequential 9.22 s 12.93 s 6 None
parallel 11.16 s 11.66 s 6 None
10k input, iterations per second (higher is better)
Boxplot for 10k, measured run time (lower is better). Sort of interesting how many “outliers” (blue dots) there are for sequential though.
1M input, iterations per second (higher is better)
Boxplot for 1M, measured run time (lower is better).
10M input, iterations per second (higher is better). Important to know, they take so long here the sample size is only 6 for each.
And just as we all expected the parallel… no wait a second the sequential version is faster for all of them? How could that be? This was easily parallelizable work, split into 3 work packages with many more cores available to do the work. Why is the parallel execution slower?
What happened here?
There’s no weird trick to this: It ran on a system with 12 physical cores that was idling save for the benchmark. Starting processes is extremely fast and lightweight, so that’s also not it. By most accounts, parallel processing should win out.
What is the problem then?
The problem here are the huge lists the tasks need to operate on and the return values that need to get back to the main process. The BEAM works on a “share nothing” architecture, this means in order to process theses lists in parallel we have to copy the lists over entirely to the process (Tasks are backed by processes). And once they’re done, we need to copy over the result as well. Copying, esp. big data structures, is both CPU intensive and memory intensive. In this case the additional copying work we do outweighs the gains we get by processing the data in parallel. You can also see that this effect seems to be diminishing the bigger the lists get – so it seems like the parallelization is catching up there.
The full copy may sound strange – after all we’re dealing with immutable data structures which should be safe to share. Well, once processes share data garbage collection becomes a whole other world of complex, or in the words of the OTP team in “A few notes on message passing” (emphasis mine):
Sending a message is straightforward: we try to find the process associated with the process identifier, and if one exists we insert the message into its signal queue.
Messages are always copied before being inserted into the queue. As wasteful as this may sound it greatly reduces garbage collection (GC) latency as the GC never has to look beyond a single process. Non-copying implementations have been tried in the past, but they turned out to be a bad fit as low latency is more important than sheer throughput for the kind of soft-realtime systems that Erlang is designed to build.
In case you’re interested in other factors for this particular benchmark: I chose the 3 functions semi-randomly looking for functions that traverse the full list at least once doing some non trivial work. If you do heavier work on the lists the parallel solution will fare better. We can also not completely discount that CPU boosting (where single core performance may increase if the other cores are idle) is shifting benchmark a bit in favor of sequential but overall it should be solid enough for demonstration purposes. Due to the low sample size for the 10M list, parallel execution may sometimes come out ahead, but usually doesn’t (and I didn’t want the benchmark take even longer).
The Sneakyness
Now, the problem here is a bit more sneaky – as we’re not explicitly sending messages. Our code looks like this: Task.async(fn -> Enum.uniq(big_list) end) – there is no send or GenServer.call here! However, that function still needs to make its way to the process for execution. As the closure of the function automatically captures referenced variables – all that data ends up being copied over as well! (Technically speaking Task.async does a send under the hood, but spawn/1 also behaves like this.)
This is what caught me off-guard with this – I knew messages were copied, but somehow Task.async was so magical I didn’t think about it sending messages or needing to copy its data to a process. Let’s call it a blind spot and broken mental model I’ve had for way too long. Hence, this blog post is for you dear reader – may you avoid the mistake I made!
Let’s also be clear here that normally this isn’t a problem and the benefits we get from this behavior are worth it. When a process terminates we can just free all its memory. It’s also not super common to shift so much data to a process to do comparatively lightweight work. The problem here is a bit, how easy it is for this problem to sneak up on you when using these high level abstractions like Task.async/1.
Real library, real problems
Yup. While I feel some shame about it, I’ve always been an advocate for sharing mistakes you made to spread some of the best leanings. This isn’t a purely theoretical thing I ran into – it stems from real problems I encountered. As you may know I’m the author of benchee – the best benchmarking library ™ 😉 . Benchee’s design, in a nut shell, revolves around a big data structure – the suite – data is enriched throughout the process of benchmarking. You may get a better idea by looking at the breakdown of the steps. This has worked great for us.
However, some of the data in that suite may reference large chunks of data if the benchmark operates on large data. Each Scenario references its given input as well as its benchmarking function. Given what we just learned both of these may be huge. More than that, the Configuration also holds all the configured inputs and is part of the suite as well.
Now, when benchee tries to compute your statistics in parallel it happily creates a new process for each scenario (which may be 20+) copying over the benchmarking function and input although it really doesn’t need them.
Even worse formatters are run in parallel handing over the entire suite – including all scenarios (function and input) as well as all the inputs again as part of the Configuration – none of which a formatter should need. 😱
To be clear, you will only encounter this problem if you deal with huge sets of data and if you do it’s “just” more memory and time used. However, for a library about measuring things and making them fast this is no good.
The remedy
Thankfully, there are multiple possible remedies for this problem:
Limiting the data you send to the absolute necessary minimum, instead of just sending the whole struct. For example, don’t send an entire Suite struct if all you need is a couple of fields.
If only the process needs the data, it may fetch the data itself instead. I.e. instead of putting the result of a giant query into the process, the process could be the one doing the query if it’s the only one that needs the data.
There are some data structures that are shared between processes and hence don’t need copying, such as ets and persistent_term.
As teased above, the most common and easiest solution is just to pass along the data you need, if you ended up accidentally sending along more than you wanted to. You can see one step of it in this pull request or this one.
The results are quite astounding, for a benchmark I’m working on (blog post coming soon ™) this change got it from practically being unable to run the benchmark due to memory constraints (on a 32GB RAM system) to easily running the benchmark – maximum resident size set size got almost halfed.
The magnitude of this can also be shown perhaps by the size of the files I saved for this benchmark. Saving is actually implemented as a formatter, and so automatically benefits from these changes – the file size for this benchmark went down from ~200MB per file to 1MB aka a reduction to 0.5% in size. You can read more about how it improved in the benchee 1.3.0 release notes.
Naturally this change will also make its way to you all as benchee 1.3.0 soon (edit: out now!).
Also when pursuing to fix this be mindful that you need to completely remove the variable from the closure. You can’t just go: Task.async(fn -> magic(suite.configuration) end) – the entire suite will still be sent along.
iex(1)> list = Enum.to_list(1..100_000)
iex(2)> # do not benchmark in iex, this is purely done to get a suite with some data
iex(3)> suite = Benchee.run(%{map: fn -> Enum.map(list, fn i -> i * i end) end })
iex(4)> :erts_debug.size(suite)
200642
iex(5)> :erts_debug.size(fn -> suite end)
200675
iex(6)> :erts_debug.size(fn -> suite.configuration end)
200841
iex(7)> :erts_debug.size(fn -> suite.configuration.time end)
201007
iex(8)> configuration = suite.configuration
iex(9)> :erts_debug.size(fn -> configuration.time end)
295
iex(10)> time = configuration.time
iex(11)> :erts_debug.size(fn -> time end)
54
Helping others avoid making the same mistake
All of that discovery, and partially shame, left me with the question: How can I help others avoid making the same mistake? Well, one part of it is right here – publish a blog post. However, that’s one point.
Also don’t forget: processes are still awesome and lightweight– you should use them! This is just a cautionary tale of how things might go wrong if you’re dealing with big chunks of data and that the work you’re doing on that data may not be extensive enough to warrant a full copy. Or that you’re accidentally sending along too much data unaware of the consequences. There are many more use cases for processes and tasks that are absolutely great, appropriate and will save you a ton of time.
What does this leave us with? As usual: don’t assume, always benchmark!
Also, be careful about the data you’re sending around and if you really need it! 💚