All the way back in June 2016 I wrote a well received blog post about tail call optimization in Elixir and Erlang. It was probably the first time I really showed off my benchmarking library benchee, it was just a couple of days after the 0.2.0 release of benchee after all.
Tools should get better over time, allow you to do things easier, promote good practices or enable you to do completely new things. So how has benchee done? Here I want to take a look back and show how we’ve improved things.
What’s better now?
In the old benchmark I had to:
- manually collect Opearting System, CPU as well as Elixir and Erlang version data
- manually create graphs in Libreoffice from the CSV output
- be reminded that performance might vary for multiple inputs
- crudely measure memory consumption in one run through on the command line
The new benchee:
- collects and shows system information
- produces extensive HTML reports with all kinds of graphs I couldn’t even produce before
- has an inputs feature encouraging me to benchmark with multiple different inputs
- is capable of doing memory measurements showing me what consumers more or less memory
I think that these are all great steps forward of which I’m really proud.
Show me the new benchmark!
Here you go, careful it’s long (implementation of MyMap for reference):
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| map_fun = fn i -> i + 1 end | |
| inputs = [ | |
| {"Small (10 Thousand)", Enum.to_list(1..10_000)}, | |
| {"Middle (100 Thousand)", Enum.to_list(1..100_000)}, | |
| {"Big (1 Million)", Enum.to_list(1..1_000_000)}, | |
| {"Bigger (5 Million)", Enum.to_list(1..5_000_000)}, | |
| {"Giant (25 Million)", Enum.to_list(1..25_000_000)} | |
| ] | |
| Benchee.run( | |
| %{ | |
| "tail-recursive" => fn list -> MyMap.map_tco(list, map_fun) end, | |
| "stdlib map" => fn list -> Enum.map(list, map_fun) end, | |
| "body-recursive" => fn list -> MyMap.map_body(list, map_fun) end, | |
| "tail-rec arg-order" => fn list -> MyMap.map_tco_arg_order(list, map_fun) end | |
| }, | |
| memory_time: 2, | |
| inputs: inputs, | |
| formatters: [ | |
| Benchee.Formatters.Console, | |
| {Benchee.Formatters.HTML, file: "bench/output/tco_focussed_detailed_inputs.html", auto_open: false} | |
| ] | |
| ) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Operating System: Linux | |
| CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz | |
| Number of Available Cores: 8 | |
| Available memory: 15.61 GB | |
| Elixir 1.8.1 | |
| Erlang 21.3.2 | |
| Benchmark suite executing with the following configuration: | |
| warmup: 2 s | |
| time: 5 s | |
| memory time: 2 s | |
| parallel: 1 | |
| inputs: Small (10 Thousand), Middle (100 Thousand), Big (1 Million), Bigger (5 Million), Giant (25 Million) | |
| Estimated total run time: 3 min | |
| # … Different ways of telling your progress … | |
| ##### With input Small (10 Thousand) ##### | |
| Name ips average deviation median 99th % | |
| tail-recursive 5.55 K 180.08 μs ±623.13% 167.78 μs 239.14 μs | |
| body-recursive 5.01 K 199.75 μs ±480.63% 190.76 μs 211.24 μs | |
| stdlib map 4.89 K 204.56 μs ±854.99% 190.86 μs 219.19 μs | |
| tail-rec arg-order 4.88 K 205.07 μs ±691.94% 163.95 μs 258.95 μs | |
| Comparison: | |
| tail-recursive 5.55 K | |
| body-recursive 5.01 K – 1.11x slower +19.67 μs | |
| stdlib map 4.89 K – 1.14x slower +24.48 μs | |
| tail-rec arg-order 4.88 K – 1.14x slower +24.99 μs | |
| Memory usage statistics: | |
| Name Memory usage | |
| tail-recursive 224.03 KB | |
| body-recursive 156.25 KB – 0.70x memory usage -67.78125 KB | |
| stdlib map 156.25 KB – 0.70x memory usage -67.78125 KB | |
| tail-rec arg-order 224.03 KB – 1.00x memory usage +0 KB | |
| **All measurements for memory usage were the same** | |
| ##### With input Middle (100 Thousand) ##### | |
| Name ips average deviation median 99th % | |
| body-recursive 473.16 2.11 ms ±145.33% 1.94 ms 6.18 ms | |
| stdlib map 459.88 2.17 ms ±174.13% 2.05 ms 6.53 ms | |
| tail-rec arg-order 453.26 2.21 ms ±245.66% 1.81 ms 6.83 ms | |
| tail-recursive 431.01 2.32 ms ±257.76% 1.95 ms 6.44 ms | |
| Comparison: | |
| body-recursive 473.16 | |
| stdlib map 459.88 – 1.03x slower +0.0610 ms | |
| tail-rec arg-order 453.26 – 1.04x slower +0.0928 ms | |
| tail-recursive 431.01 – 1.10x slower +0.21 ms | |
| Memory usage statistics: | |
| Name Memory usage | |
| body-recursive 1.53 MB | |
| stdlib map 1.53 MB – 1.00x memory usage +0 MB | |
| tail-rec arg-order 2.89 MB – 1.89x memory usage +1.36 MB | |
| tail-recursive 2.89 MB – 1.89x memory usage +1.36 MB | |
| **All measurements for memory usage were the same** | |
| ##### With input Big (1 Million) ##### | |
| Name ips average deviation median 99th % | |
| stdlib map 43.63 22.92 ms ±59.63% 20.78 ms 38.76 ms | |
| body-recursive 42.54 23.51 ms ±58.73% 21.11 ms 50.95 ms | |
| tail-rec arg-order 41.68 23.99 ms ±83.11% 22.36 ms 35.93 ms | |
| tail-recursive 40.02 24.99 ms ±82.12% 23.33 ms 55.25 ms | |
| Comparison: | |
| stdlib map 43.63 | |
| body-recursive 42.54 – 1.03x slower +0.59 ms | |
| tail-rec arg-order 41.68 – 1.05x slower +1.07 ms | |
| tail-recursive 40.02 – 1.09x slower +2.07 ms | |
| Memory usage statistics: | |
| Name Memory usage | |
| stdlib map 15.26 MB | |
| body-recursive 15.26 MB – 1.00x memory usage +0 MB | |
| tail-rec arg-order 26.95 MB – 1.77x memory usage +11.70 MB | |
| tail-recursive 26.95 MB – 1.77x memory usage +11.70 MB | |
| **All measurements for memory usage were the same** | |
| ##### With input Bigger (5 Million) ##### | |
| Name ips average deviation median 99th % | |
| stdlib map 8.89 112.49 ms ±44.68% 105.73 ms 421.33 ms | |
| body-recursive 8.87 112.72 ms ±44.97% 104.66 ms 423.24 ms | |
| tail-rec arg-order 8.01 124.79 ms ±40.27% 114.70 ms 425.68 ms | |
| tail-recursive 7.59 131.75 ms ±40.89% 121.18 ms 439.39 ms | |
| Comparison: | |
| stdlib map 8.89 | |
| body-recursive 8.87 – 1.00x slower +0.23 ms | |
| tail-rec arg-order 8.01 – 1.11x slower +12.30 ms | |
| tail-recursive 7.59 – 1.17x slower +19.26 ms | |
| Memory usage statistics: | |
| Name Memory usage | |
| stdlib map 76.29 MB | |
| body-recursive 76.29 MB – 1.00x memory usage +0 MB | |
| tail-rec arg-order 149.82 MB – 1.96x memory usage +73.53 MB | |
| tail-recursive 149.82 MB – 1.96x memory usage +73.53 MB | |
| **All measurements for memory usage were the same** | |
| ##### With input Giant (25 Million) ##### | |
| Name ips average deviation median 99th % | |
| tail-rec arg-order 1.36 733.10 ms ±25.65% 657.07 ms 1099.94 ms | |
| tail-recursive 1.28 780.13 ms ±23.89% 741.42 ms 1113.52 ms | |
| stdlib map 1.25 800.63 ms ±27.17% 779.22 ms 1185.27 ms | |
| body-recursive 1.23 813.35 ms ±28.45% 790.23 ms 1224.44 ms | |
| Comparison: | |
| tail-rec arg-order 1.36 | |
| tail-recursive 1.28 – 1.06x slower +47.03 ms | |
| stdlib map 1.25 – 1.09x slower +67.53 ms | |
| body-recursive 1.23 – 1.11x slower +80.25 ms | |
| Memory usage statistics: | |
| Name Memory usage | |
| tail-rec arg-order 758.55 MB | |
| tail-recursive 758.55 MB – 1.00x memory usage +0 MB | |
| stdlib map 381.47 MB – 0.50x memory usage -377.08060 MB | |
| body-recursive 381.47 MB – 0.50x memory usage -377.08060 MB | |
| **All measurements for memory usage were the same** | |
| # where did benchee write all the files |
We can easily see that the tail recursive functions seem to always consume more memory. Also that our tail recursive implementation with the switched argument order is mostly faster than its sibling (always when we look at the median which is worthwhile if we want to limit the impact of outliers).
Such an (informative) wall of text! How do we spice that up a bit? How about the HTML report generated from this? It contains about the same data but is enhanced with some nice graphs for comparisons sake:


It doesn’t stop there though, some of my favourite graphs are the once looking at individual scenarios:

This Histogram shows us the distribution of the values pretty handily. We can easily see that most samples are in a 100Million – 150 Million Nanoseconds range (100-150 Milliseconds in more digestible units, scaling values in the graphs is somewhere on the road map ;))

Here we can just see the raw run times in order as they were recorded. This is helpful to potentially spot patterns like gradually increasing/decreasing run times or sudden spikes.
Something seems odd?
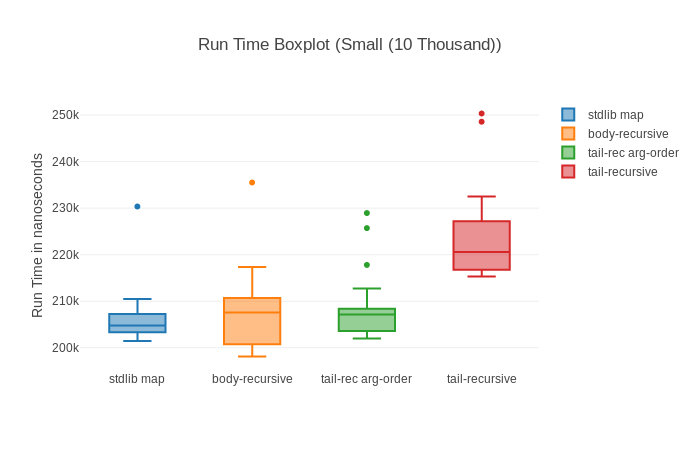
Speaking about spotting, have you noticed anything in those graphs? Almost all of them show that some big outliers might be around screwing with our results. The basic comparison shows pretty big standard deviation, the box plot one straight up shows outliers (little dots), the histogram show that for a long time there’s nothing and then there’s a measurement that’s much higher and in the raw run times we also see one enormous spike.
All of this is even more prevalent when we look at the graphs for the small input (10 000 elements):

Why could this be? Well, my favourite suspect in this case is garbage collection. It can take quite a while and as such is a candidate for huge outliers – the more so the faster the benchmarks are.
So let’s try to take garbage collection out of the equation. This is somewhat controversial and we can’t take it out 100%, but we can significantly limit its impact through benchee’s hooks feature. Basically through adding after_each: fn _ -> :erlang.garbage_collect() end to our configuration we tell benchee to run garbage collection after every measurement to minimize the chance that it will trigger during a measurement and hence affect results.
You can have a look at it in this HTML report. We can immediately see in the results and graphs that standard deviation got a lot smaller and we have way fewer outliers now for our smaller input sizes:

Note however that our sample size also went down significantly (from over 20 000 to… 30) so increasing benchmarking time might be worth while to get more samples again.
How does it look like for our big 5 Million input though?

Not much of an improvement… Actually slightly worse. Strange. We can find the likely answer in the raw run time graphs of all of our contenders:


The first sample is always the slowest (while running with GC it seemed to be the third run). My theory is that for the larger amount of data the BEAM needs to repeatedly grow the memory of the process we are benchmarking. This seems strange though, as that should have already happened during warmup (benchee uses one process for each scenario which includes warmup and run time). It might be something different, but it very likely is a one time cost.
To GC or not to GC
Is a good question. Especially for very micro benchmarks it can help stabilize/sanitize the measured times. Due to the high standard deviation/outliers whoever is fastest can change quite a lot on repeated runs.
However, Garbage Collection happens in a real world scenario and the amount of “garbage” you produce can often be directly linked to your run time – taking the cleaning time out of equation can yield results that are not necessarily applicable to the real world. You could also significantly increase the run time to level the playing field so that by the law of big numbers we come closer to the true average – spikes from garbage collection or not.
Wrapping up
Anyhow, this was just a little detour to show how some of these graphs can help us drill down and find out why our measurements are as they are and find likely causes.
The improvements in benchee mean the promotion of better practices and much less manual work. In essence I could just link the HTML report and then just discuss the topic at hand (well save the benchmarking code, that’s not in there… yet 😉 ) which is great for publishing benchmarks. Speaking about discussions, I omitted the discussions around tail recursive calls etc. with comments from José Valim and Robert Virding. Feel free to still read the old blog post for that – it’s not that old after all.
Happy benchmarking!

